
Transformers: The Architecture That Changed AI
Published:

Why it matters
Transformers are the common backbone behind LLMs, vision-language models, speech models, and a growing share of scientific AI.
Core mechanism
Every token can directly inspect every other token through self-attention, instead of waiting for information to travel step by step.
What to learn next
Attention, QKV, masking, residuals, and positional encodings are the five ideas that make the whole architecture click.
The Problem with the Old Way
Before 2017, the go-to model for text was the Recurrent Neural Network (RNN). It worked like a conveyor belt: read one word, update a hidden state, pass it to the next word. The trouble is that by the time you reach the end of a long sentence, the beginning is already fading — the network forgets.
This is the vanishing gradient problem: information from far-back positions barely influences the model. Researchers patched it with LSTMs and GRUs, but the fundamental bottleneck remained: you can’t parallelise a sequential process. Training was slow, and long-range dependencies were hard to capture.
The Core Insight: Attend to Everything
The 2017 paper Attention Is All You Need (Vaswani et al.) asked: what if you let every word look directly at every other word, with no middle layers in between?
That’s self-attention. Each token computes a score with every other token, learns which ones are relevant, and mixes their information together — in one parallel step. No sequential dependency. No forgetting.
The Big Picture in One Pass
If you strip away the implementation details, a Transformer does five things:
- Turn tokens into vectors.
- Inject position information, because attention alone is order-agnostic.
- Let tokens exchange information via self-attention.
- Stabilise deep training with residual connections and layer normalisation.
- Refine each token independently with a feed-forward network.
That recipe is simple enough to reuse across domains, which is why the same core architecture reappears in language, vision, audio, biology, robotics, and multi-modal systems.
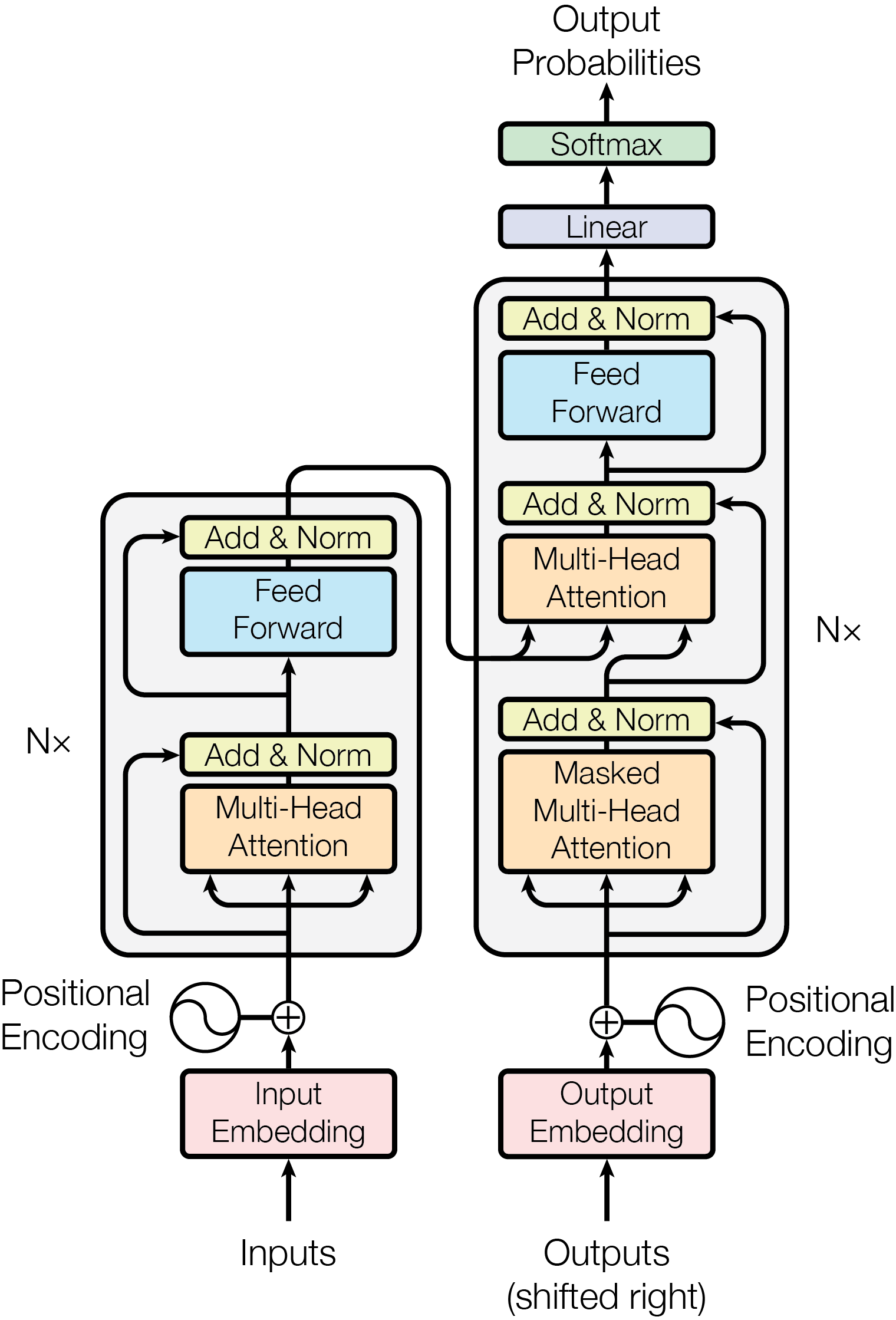
Architecture Walk-Through
A Transformer encoder consists of these building blocks, stacked N times:
1. Token Embedding
Each word (or subword token) is mapped to a dense vector — a point in high-dimensional space where similar words land close together.
2. Positional Encoding
Because attention sees all tokens simultaneously, the model would otherwise have no idea which word comes first. Positional encodings inject position information into each token’s vector before it enters the attention layers. (See the dedicated PE posts for all the variants.)
3. Multi-Head Self-Attention
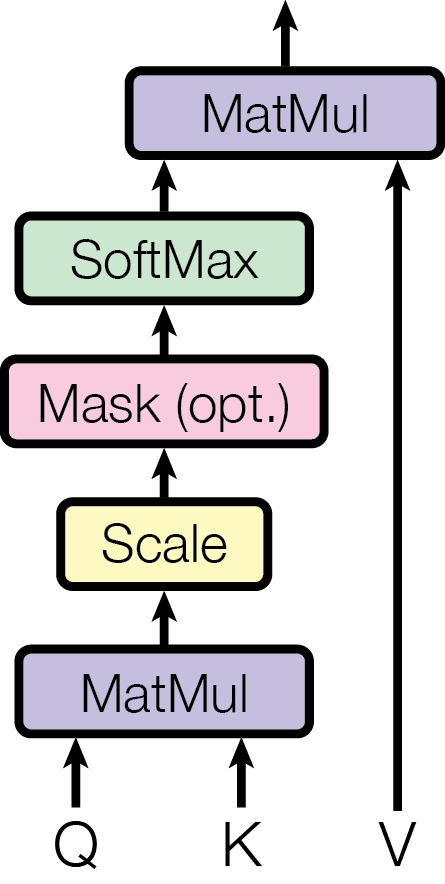
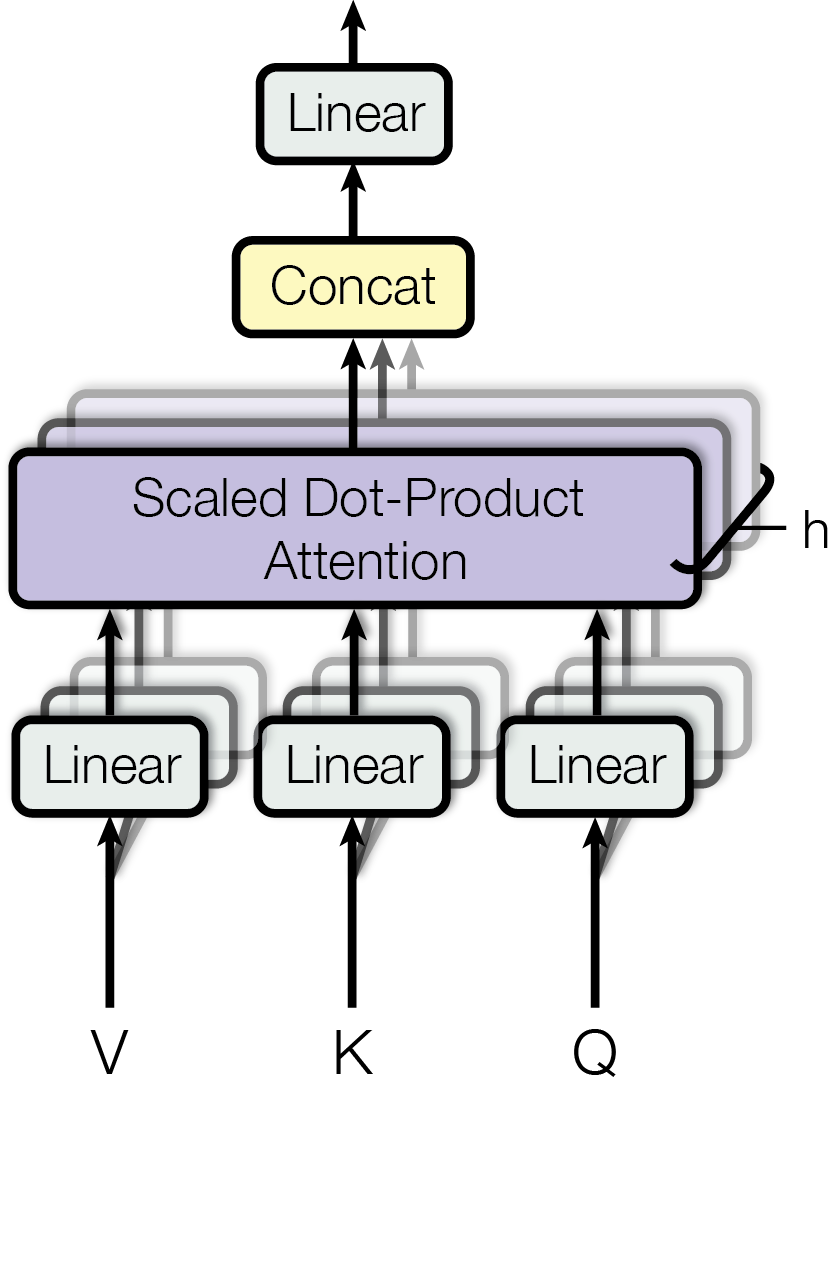
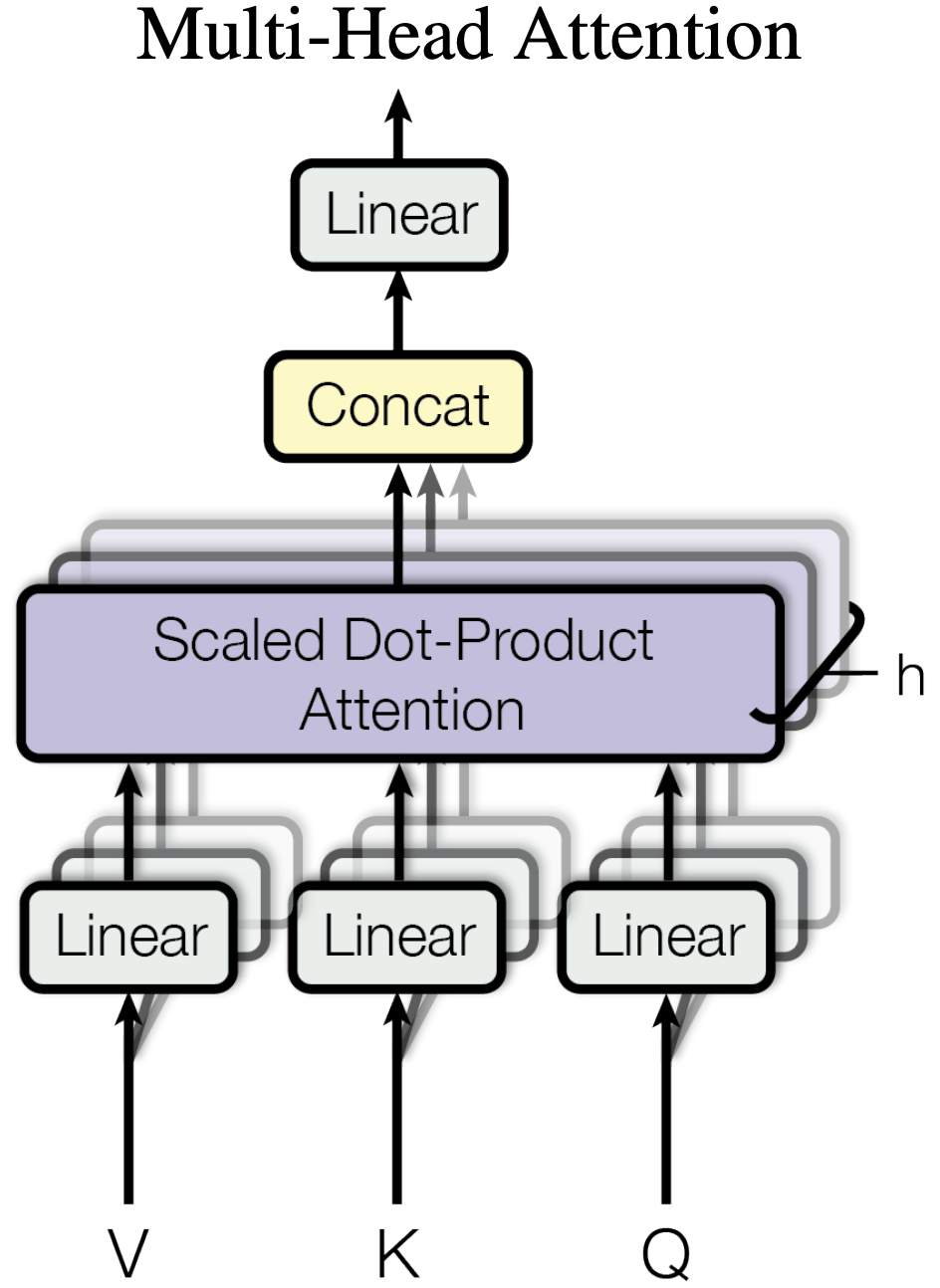
This is the heart of the Transformer. Each token computes three vectors — a Query (what I’m looking for), a Key (what I offer), and a Value (what I’ll contribute). The model computes pairwise relevance scores, normalises them with a softmax, then mixes the value vectors accordingly. Running this process in parallel across h heads lets the model capture different types of relationships simultaneously.
4. Add & Layer Norm
A residual connection adds the attention output back to the input, then layer normalisation stabilises training. This pattern repeats after every sub-layer and is crucial for training deep stacks.
5. Feed-Forward Network
Two linear layers with a non-linearity (typically GELU or ReLU) applied independently to each token position. This is where the model “thinks” about each token after mixing information via attention.
Reading Roadmap
- Start with Self-Attention and Scaled Dot-Product Attention.
- Then learn QKV, attention masks, and multi-head attention.
- After that, study positional encodings and their modern long-context variants.
- Finally, zoom out with The Transformer Block to see how everything composes into one layer.
Where Transformers Are Used Today
| Domain | Model | What it does |
|---|---|---|
| Language | GPT-4, LLaMA 3 | Generate and understand text |
| Language | BERT, RoBERTa | Classify, extract, embed text |
| Vision | ViT, Swin | Classify and segment images |
| Audio | Whisper | Transcribe speech |
| Biology | AlphaFold 2 | Predict protein structure |
| Multi-modal | CLIP, Gemini | Connect text + images |
Encoders, Decoders, and Hybrids
- Encoder-only (BERT): reads the full sequence bidirectionally; great for understanding tasks.
- Decoder-only (GPT): reads left-to-right and predicts the next token; great for generation.
- Encoder–Decoder (T5, original Transformer): encodes a source sequence, then decodes a target; great for translation and summarisation.
Why the Architecture Scaled So Well
Transformers won not because attention is mathematically elegant, but because the whole stack lines up with modern compute:
- self-attention parallelises well on GPUs and TPUs;
- the same layer can be repeated dozens or hundreds of times;
- the architecture does not assume language specifically, only sequences of tokens;
- scaling data, model size, and context length tends to improve performance smoothly.
That combination made Transformers less like a one-off NLP model and more like a general-purpose interface between data and computation.
What This Overview Should Leave You With
The Transformer is not one trick. It is a clean composition of simple blocks that together solve three hard problems at once:
- how to model long-range dependencies;
- how to train efficiently at scale;
- how to reuse the same backbone across many data types.
✅ Key Takeaways
- Transformers replaced sequential RNNs with parallel self-attention.
- Each layer has two sub-layers: multi-head attention and a feed-forward network, both with residual connections.
- Positional encodings compensate for the order-agnostic nature of attention.
- The same architecture works across text, images, audio, and biology by changing inputs and objectives.
References
- [1] Vaswani, A. et al. (2017). Attention Is All You Need.
- Devlin, J. et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- Dosovitskiy, A. et al. (2020). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.
- [2] https://www.sscardapane.it/alice-book/
- Zhang, Lipton, Li, and Smola. Dive into Deep Learning, chapters on attention and Transformers.