
Self-Attention: Teaching Machines to Focus
Published:
The Focusing Analogy
Imagine reading a paper and highlighting sentences that are relevant to your current question. Self-attention does something similar: for every word in a sentence, it calculates a relevance score against every other word, then creates a new representation that is a blend of the most relevant words.
Consider: “The animal didn’t cross the street because it was too tired.”
What does “it” refer to? To understand this, the model needs to relate “it” to “animal” (not “street”). Self-attention learns to assign a high score to that pair.
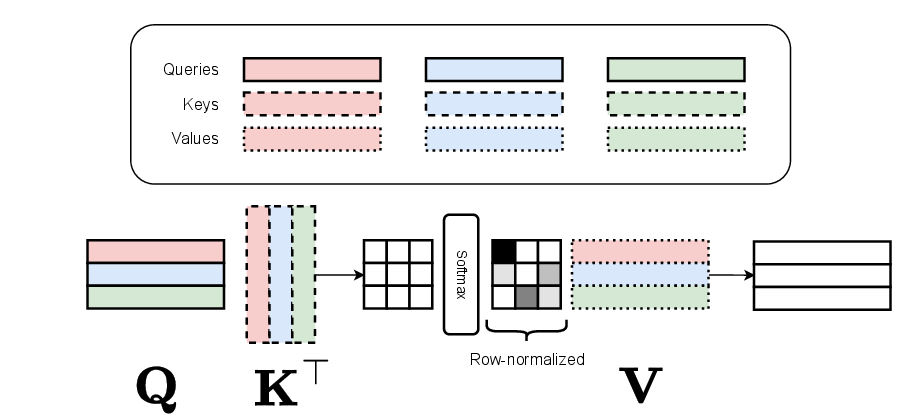
Query, Key, and Value
Self-attention introduces three projections from each token’s embedding vector:
- Query (Q): “What am I looking for?”
- Key (K): “What do I contain?”
- Value (V): “What will I contribute if selected?”
Think of it like a library search system:
- You submit a Query (your search request).
- Every book has a Key (its index entry).
- The relevance between your query and each key determines how much of each book’s Value (its content) you receive.
Each of Q, K, V is produced by multiplying the token’s embedding by a learned weight matrix: Q = X·W_Q, K = X·W_K, V = X·W_V.
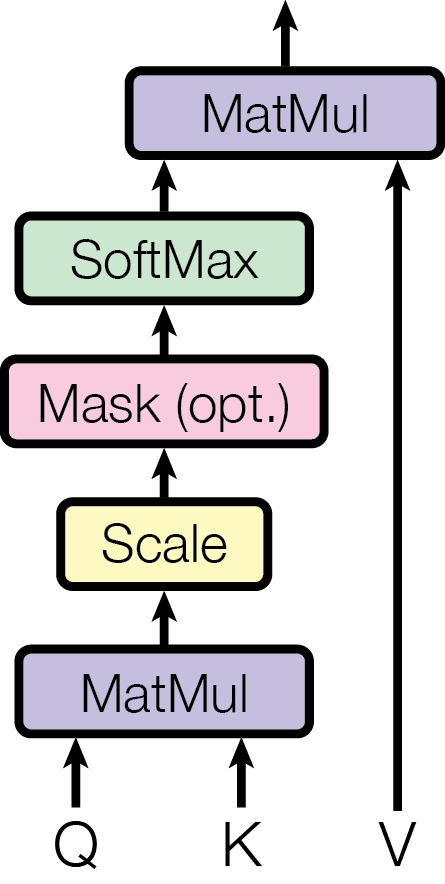
The Four-Step Computation
Step 1 — Project: Multiply the input matrix X by three weight matrices to get Q, K, V.
Step 2 — Score: Compute the dot product of every query with every key: Q · Kᵀ. Divide by √dₖ to prevent large values from pushing the softmax into saturation.
Step 3 — Normalise: Apply softmax row-wise. Each row now sums to 1, giving a probability distribution: “how much should token i attend to token j?”
Step 4 — Mix: Multiply the attention weights by V. Each token’s output is a weighted average of all value vectors — heavily weighted towards the tokens it found most relevant.
Why Divide by √dₖ?
Without scaling, the dot products grow large as dimensionality dₖ increases (because they’re sums of dₖ products). Large values push softmax into regions where gradients are tiny, slowing training. Dividing by √dₖ keeps the variance stable regardless of model size.
What the Scores Represent
The attention matrix has a score for every (query-token, key-token) pair. High score = “I find you useful.” After softmax, these are weights that determine how much each token borrows from each other token when forming its output representation.
Critically, this computation is fully differentiable — the model learns which token pairs should have high attention purely from training signal, with no hand-crafted rules.
Concrete Worked Example (2-token sequence, d_k = 2)
Let’s trace the full computation with tiny numbers so you can verify it by hand.
Setup: two tokens “cat” (x₁) and “sat” (x₂), d_k = 2.
Suppose after projection we have:
- Q = [[1, 0], [0, 1]] — q₁ = [1,0], q₂ = [0,1]
- K = [[1, 0], [0, 1]] — k₁ = [1,0], k₂ = [0,1]
- V = [[2, 3], [5, 1]] — v₁ = [2,3], v₂ = [5,1]
Step 1 — Raw scores (Q · Kᵀ):
k₁=[1,0] k₂=[0,1]
q₁=[1,0] 1·1+0·0=1 1·0+0·1=0
q₂=[0,1] 0·1+1·0=0 0·0+1·1=1
Score matrix = [[1, 0], [0, 1]]
Step 2 — Scale by √d_k = √2 ≈ 1.41:
Scaled = [[0.71, 0], [0, 0.71]]
Step 3 — Softmax row-wise:
Row 1: softmax([0.71, 0]) = [e^0.71 / (e^0.71+1), 1/(e^0.71+1)] ≈ [0.67, 0.33]
Row 2: softmax([0, 0.71]) ≈ [0.33, 0.67]
Step 4 — Weighted sum of V:
Output₁ = 0.67·[2,3] + 0.33·[5,1] = [1.34+1.65, 2.01+0.33] = [2.99, 2.34]
Output₂ = 0.33·[2,3] + 0.67·[5,1] = [0.66+3.35, 0.99+0.67] = [4.01, 1.66]
What Self-Attention Gives You That RNNs Do Not
- Direct long-range access: the last token can attend to the first token immediately.
- Parallelism: all token pairs are processed at once on modern hardware.
- Task-specific structure: the model learns what counts as a useful dependency instead of relying on fixed linguistic rules.
- Flexible context mixing: the same mechanism can capture syntax, coreference, topic, and retrieval-like behavior.
References
- Vaswani, A., et al. (2017). Attention Is All You Need. NeurIPS 2017.
- Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural Machine Translation by Jointly Learning to Align and Translate.
- [2] https://www.sscardapane.it/alice-book/
✅ Key Takeaways
- Self-attention projects each token into Q, K, V vectors via learned weight matrices.
- Relevance scores are dot products of Q and K, scaled by √d_k and normalised with softmax.
- The output of each token is a weighted sum of all Value vectors.
- The whole computation runs in parallel across all token pairs — no sequential dependency.