
Positional Encodings: Why Position Matters
Published:
The Order-Agnostic Problem
Self-attention computes pairwise scores between all tokens. It doesn’t matter if token A is first or last — the attention equation treats both identically. Shuffle the sentence and the model gets the exact same output (just with rows permuted).
This is catastrophic for language: “dog bites man” and “man bites dog” have opposite meanings.
The Solution: Inject Position into the Embedding
The fix is conceptually simple: before the first attention layer, add a position-dependent vector to each token’s embedding.
final_input[pos] = token_embedding[pos] + positional_encoding[pos]
The attention mechanism then sees the mixed vector and can pick up position information from it. Simple. But the choice of what those position vectors are turns out to matter a lot.
The Landscape of PE Methods
| Method | Type | Learnable? | Extrapolates? | Used in |
|---|---|---|---|---|
| Sinusoidal | Absolute | No | Moderate | Original Transformer (2017) |
| Learned Absolute | Absolute | Yes | No | BERT, GPT-1, ViT |
| Relative (Shaw) | Relative | Yes | Yes | Music Transformer |
| Relative (T5 Bias) | Relative | Yes | Yes | T5, Flan-T5 |
| RoPE | Rotary (Absolute→Relative) | No | Good | LLaMA, Mistral, GPT-NeoX |
| ALiBi | Attention bias | No | Excellent | BLOOM, MPT |
Three Axes to Understand PEs
1. Absolute vs. Relative Absolute methods assign a vector to each position index (0, 1, 2, …). Relative methods instead encode the distance between two tokens (±1, ±2, …). Relative encodings tend to generalise better across lengths.
2. Fixed vs. Learned Fixed methods (sinusoidal, ALiBi) use a deterministic formula — no extra parameters. Learned methods (BERT-style, relative biases) train position representations end-to-end. Learned = more flexible; fixed = no max-length constraint.
3. Extrapolation Can the model handle sequences longer than those seen during training? This is the key practical question for LLMs serving long documents. ALiBi and RoPE generally win here; standard learned absolute PEs fail badly.
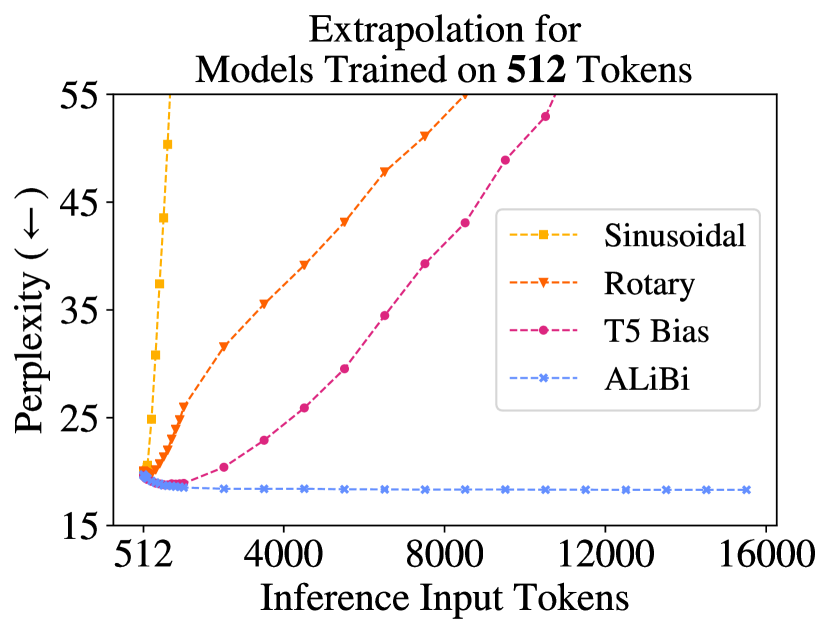
Which PE Should You Reach For?
- If you want the historical baseline, start with sinusoidal PE.
- If you care about simple pretraining on fixed lengths, learned absolute PE is easy.
- If you care about relative order and text-to-text transfer, T5-style relative bias is strong.
- If you care about modern LLMs and long context, RoPE is the default starting point.
- If you care about extreme extrapolation with minimal machinery, ALiBi is still conceptually elegant.
References
- Vaswani, A., et al. (2017). Attention Is All You Need.
- Shaw, P., Uszkoreit, J., & Vaswani, A. (2018). Self-Attention with Relative Position Representations.
- Raffel, C., et al. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.
- Su, J., et al. (2021). RoFormer: Enhanced Transformer with Rotary Position Embedding.
- Press, O., Smith, N. A., & Lewis, M. (2022). Train Short, Test Long: Attention with Linear Biases.
- [2] https://www.sscardapane.it/alice-book/
✅ Key Takeaways
- Self-attention is order-agnostic; PEs inject position information as vectors added to token embeddings.
- The main design axes are: absolute vs. relative, fixed vs. learned, extrapolation capability.
- Modern LLMs (LLaMA, Mistral, BLOOM) moved away from sinusoidal PEs toward RoPE and ALiBi.
- Each subsequent chapter covers one PE method in depth — start with sinusoidal to understand the origin.