
SheafPool: Basis-Invariant Graph Readout for Sheaf Neural Networks
Published:

The Problem: Pooling in Sheaf Models Is Not Ordinary Pooling
In a standard graph neural network, graph classification is conceptually simple: run message passing, get one embedding per node, then pool those embeddings with a sum, mean, or attention readout. That works because every node embedding lives in the same vector space.
In a sheaf neural network, this assumption breaks. Each node feature is not just a plain vector in one shared ambient space. It lives in a local stalk, which means it is represented in a node-specific coordinate frame. Even if all stalks have the same dimensionality, there is no canonical reason why the basis at node $u$ should line up with the basis at node $v$.
So naive pooling creates a real geometric bug: averaging stalk vectors directly can mix coordinates that mean different things in different local frames. The graph embedding then depends on arbitrary basis choices rather than only on the graph itself.
What SheafPool Tries to Preserve
The goal is not merely to compress node information. The goal is to compress it in a way that respects the gauge structure of the sheaf. A correct readout should be:
- Permutation-invariant across nodes, as any graph pooling should be.
- Basis-invariant across local stalk frames.
- Expressive enough to preserve graph-level differences after alignment.
That second requirement is the new one. It is what makes SheafPool different from ordinary mean/sum pooling and from most standard attention readouts.
The Core Idea
SheafPool builds a graph embedding in stages:
- Whiten each stalk representation so scale and covariance distortions are removed locally.
- Align stalks to a shared anchor frame so residual rotational ambiguity is resolved consistently across nodes.
- Compute invariant attention weights from channel-wise energies rather than basis-dependent raw coordinates.
- Pool the aligned stalks into a receive-only graph token.
- Collapse the pooled token into graph features using invariant channel-wise energies.
The big picture is simple: before you aggregate, make sure the quantities you aggregate are actually comparable.
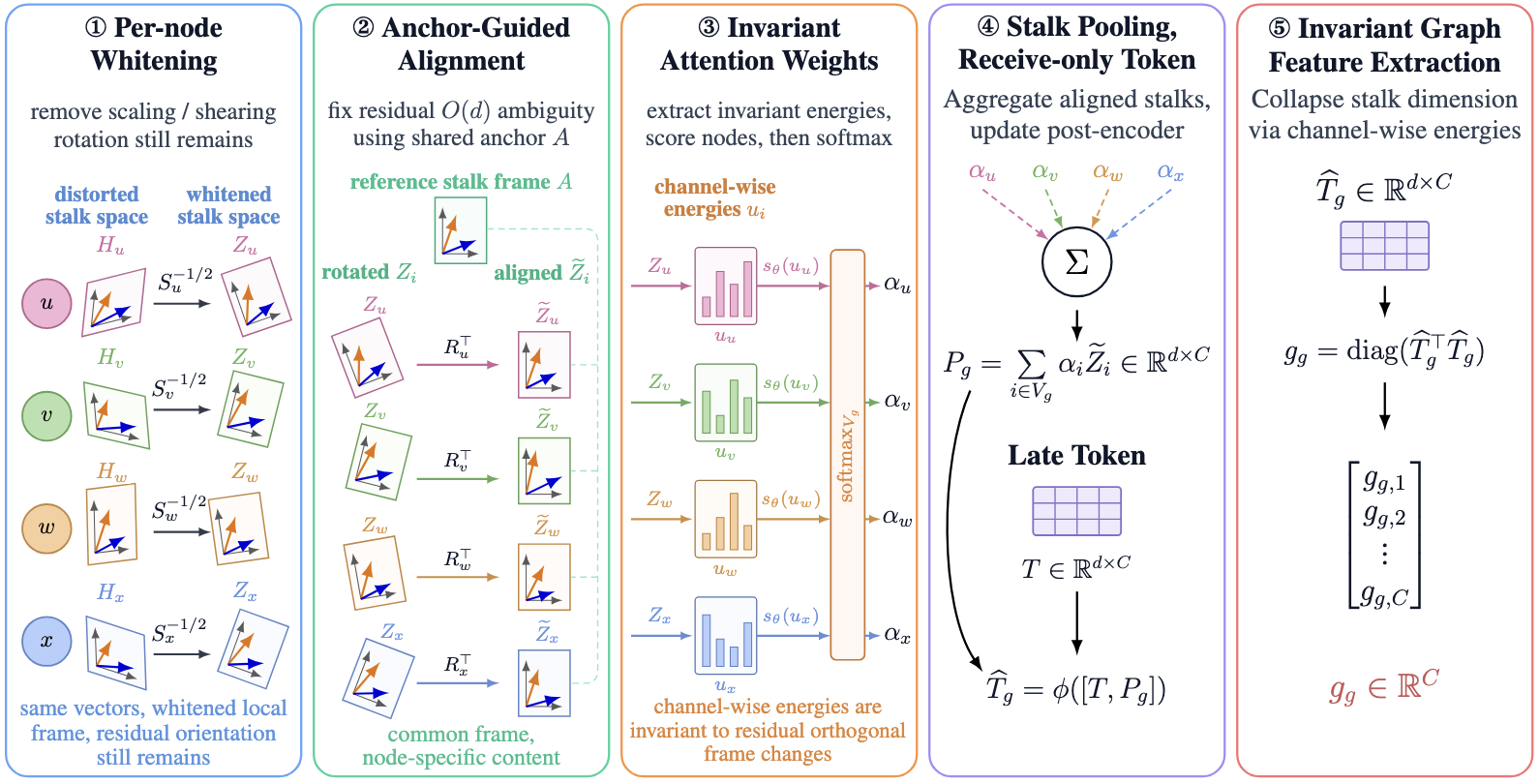
Why Whitening and Alignment Are Both Needed
Whitening alone is not enough. It removes scale distortions and correlation structure, but it still leaves a residual orthogonal ambiguity: two whitened stalks can represent the same content under different rotations.
That is why the second step matters. SheafPool introduces an anchor-guided alignment procedure that maps each whitened stalk into a common reference frame. After this step, the vectors are not just normalised; they are oriented consistently enough to be aggregated meaningfully.
This is the key conceptual move in the method. SheafPool is not saying “pool better.” It is saying: alignment must happen before pooling, otherwise graph-level classification in sheaf space is not properly defined.
Why the Attention Weights Are Different
The attention mechanism inside SheafPool is also designed carefully. If the weights were computed directly from raw stalk coordinates, they would inherit the same basis dependence as naive pooling.
Instead, the paper builds attention weights from invariant energies. That way, the score assigned to a node depends on content that survives a local basis change. So both parts of the readout are protected:
- the features being pooled are aligned first;
- the weights used to pool them are themselves invariant.
That combination is what makes the readout genuinely geometric rather than just heuristic.
Numerical Example: d=2 Basis Invariance Step by Step
Consider two nodes with d=2 stalks before pooling:
- h₁ = [2, 0] (a vector pointing along the x-axis with magnitude 2)
- h₂ = [0, 3] (a vector pointing along the y-axis with magnitude 3)
| Step 1 — Whitening. Whitening normalises each stalk by its own Euclidean norm (or covariance, depending on the implementation). Using norm-whitening: h₁’ = h₁ / | h₁ | = [2,0] / 2 = [1, 0], and h₂’ = h₂ / | h₂ | = [0,3] / 3 = [0, 1]. |
Step 2 — Alignment. The anchor frame is the identity I. Both [1,0] and [0,1] are already orthonormal, so they are in canonical form after alignment. No rotation is needed in this example.
| Step 3 — Invariant energies. The channel-wise energy for each stalk is E_i = | h_i’ | ². Since h₁’ and h₂’ are unit vectors: E₁ = | [1,0] | ² = 1 and E₂ = | [0,1] | ² = 1. |
Step 4 — Graph representation. The pooled graph feature vector is [E₁, E₂] = [1, 1].
Basis invariance check. Now scale h₁ by 2: h₁_scaled = [4, 0]. After whitening: [4,0] / 4 = [1, 0] — the same unit vector as before. The invariant energy E₁ = 1 is unchanged. The graph embedding [1, 1] is identical. This demonstrates that SheafPool’s readout is scale-invariant: doubling a stalk vector does not change the graph embedding, because the relevant information is the direction (captured by the whitened vector) not the magnitude.
Why this matters. Without whitening, the naive mean pool of h₁=[2,0] and h₂=[0,3] gives [1.0, 1.5] — while the naive mean of [4,0] and [0,3] gives [2.0, 1.5]. These are different graph embeddings for what is structurally the same graph under a local basis change. SheafPool eliminates this spurious dependence on local coordinate scale.
What It Buys in Practice
In the HetSheaf paper, SheafPool is used for graph classification and yields a very large improvement over naive mean pooling. The gain is not a small optimization detail. It is evidence that graph-level sheaf learning needs a dedicated readout design rather than a borrowed GNN pooling trick.
The practical message is:
- sheaf models are naturally strong at node- and edge-level relational geometry;
- graph-level tasks need an additional mechanism to compare local stalk information consistently;
- SheafPool is that missing bridge.
Why This Matters Beyond HetSheaf
SheafPool is important even outside heterogeneous graphs. Any future sheaf GNN that wants to do graph classification, graph retrieval, or graph-level reasoning faces the same problem: local stalk representations are not globally aligned by default.
So SheafPool should be read as more than one component in one paper. It is an answer to a general question in sheaf deep learning:
What is the right graph-level readout when node features live in local geometric frames?
That is why it is a useful concept to understand on its own.
References
- Braithwaite, L., Borgi, A., Onorato, G., Tarantelli, K., Restuccia, F., Silvestri, F., & Liò, P. (2024). Heterogeneous Sheaf Neural Networks.
✅ Key Takeaways
- SheafPool addresses a real geometric failure mode: naive pooling of stalk vectors is basis-dependent and therefore ill-defined.
- The method aligns local stalk representations into a shared canonical frame before aggregation.
- Its attention weights are also built from invariant quantities, not raw basis-dependent coordinates.
- SheafPool is the graph-level readout mechanism that makes sheaf-based graph classification principled.