
GAPE: Remember to Forget — Gated Adaptive Positional Encoding
Published:

Intuition First: Selective Forgetting
Imagine you are reading a 50-page document and must answer a question about a single crucial sentence on page 3. As you reach page 50, you have seen 49 pages of largely irrelevant content. A good reader can suppress the noise and keep page 3’s key sentence accessible. A poor reader’s working memory fills with distractor content and the crucial fact fades.
RoPE at long context is the poor reader. All distant tokens — the crucial needle and the distracting haystack — are treated identically by the positional encoding. Once context grows beyond the training window, the rotary phases lose their calibration and attention spreads diffusely over everything.
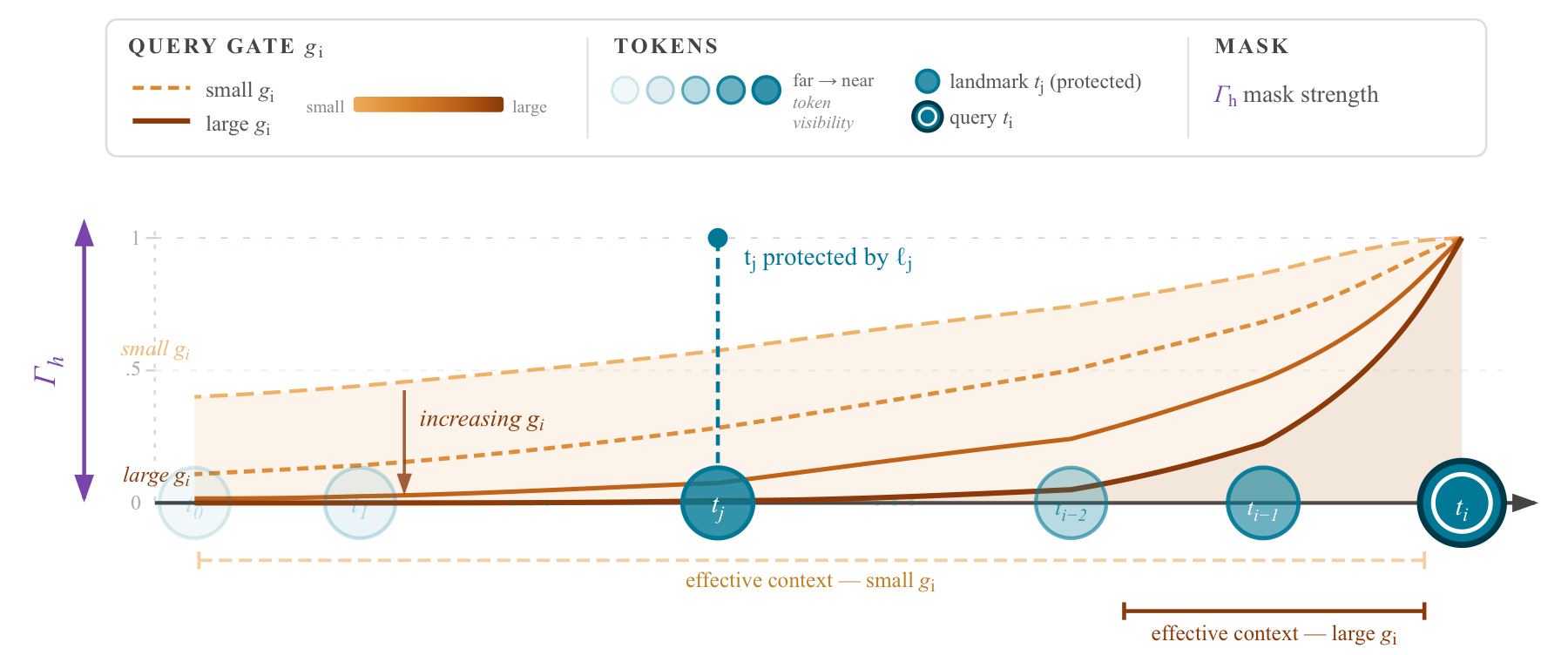
GAPE gives the model two explicit knobs:
- Query gate g_i: “how strongly should query i suppress everything far away?” — the forgetting dial.
- Key (landmark) gate l_j: “is key j important enough that no query should forget it?” — the protection dial.
The model learns, for each head and layer, its own policy for what to forget and what to preserve.
The RoPE Long-Context Problem
Rotary Positional Encoding (RoPE) is the positional scheme used in almost every modern LLM — LLaMA, Mistral, Gemma, Qwen. It encodes position by rotating query and key vectors in frequency-specific planes, so the dot-product between a query at position m and a key at position n depends only on their relative distance m−n.
This works beautifully within the training range. But when you extend context beyond what the model saw during training:
- Rotary phases at large relative distances enter out-of-distribution regimes — the model has never seen those angular configurations.
- Attention becomes diffuse: scores spread across irrelevant distant tokens rather than concentrating on relevant ones.
- Spurious long-range alignments emerge: distant tokens with “accidentally” matching OOD rotary phases receive high attention.
Existing fixes (RoPE scaling, YaRN, LONGROPE) mostly rescale frequencies to handle longer ranges, but they trade local positional resolution for global stability. None target the content mismatch between relevant and irrelevant distant tokens.
The Key Observation
RoPE failures at long context are not only positional. They are selective-attention failures. The model does not simply lose all distant information; it loses the ability to distinguish useful distant tokens from distracting distant tokens. GAPE targets exactly that failure mode by modifying the logits with content-aware gates rather than reparameterising the rotary angles themselves.
GAPE: Two Gates on the Logits
GAPE introduces a content-aware additive mask directly into the pre-softmax attention logits. In the paper notation, the attention logit is written as:
\[a_{i,j} = \frac{1}{\sqrt{d}} \mathbf{q}_i^\top R_\Theta(i-j)\mathbf{k}_j + M_{i,j}\]with GAPE mask:
\[M_{i,j} = \Gamma_h g_i \left(\frac{j(1-l_j)}{T} + \frac{i\,l_j}{T}\right).\]The routing variables are defined in the paper as:
Landmark gate:
\[l_j = \sigma(\mathbf{w}_l^\top \mathbf{k}_j + b_l)\]Query gate:
\[g_i = \operatorname{Softplus}(\mathbf{w}_g^\top \mathbf{q}_i + b_g)\]Head amplitude:
\[\Gamma_h = \operatorname{Softplus}(\gamma_h)\]This is the key decoupling: $g_i$ controls how strongly query $i$ suppresses unprotected distant context, while $l_j$ marks key $j$ as a landmark that should be protected from that suppression. RoPE’s rotary geometry remains untouched because the structural intervention enters additively through $M_{i,j}$ rather than by changing the rotations themselves.
Why the Factorisation Matters
If the bias were only query-dependent, the model could suppress distance but would have no mechanism to rescue rare important tokens. If it were only key-dependent, salient keys could be marked, but irrelevant long-range attention would still remain too diffuse. The product structure gives both effects at once: broad contraction plus selective preservation.
Theoretical Guarantee
The paper proves that protected tokens (high landmark-gate value $l_j$) remain accessible regardless of distance: their effective attention logit is preserved by the protection term in the mask. Conversely, for unprotected tokens, the attention mass decays as a function of the query gate value $g_i$, giving a formal “forgetting” property for irrelevant context.
Empirical Validation
NIAH: Needle-in-a-Haystack Retrieval
The Needle-in-a-Haystack (NIAH) benchmark places a critical fact (the “needle”) at various positions in a long context and asks the model to retrieve it. GAPE consistently places sharper attention on the needle token at all context lengths and needle positions, even at 4× training context length.
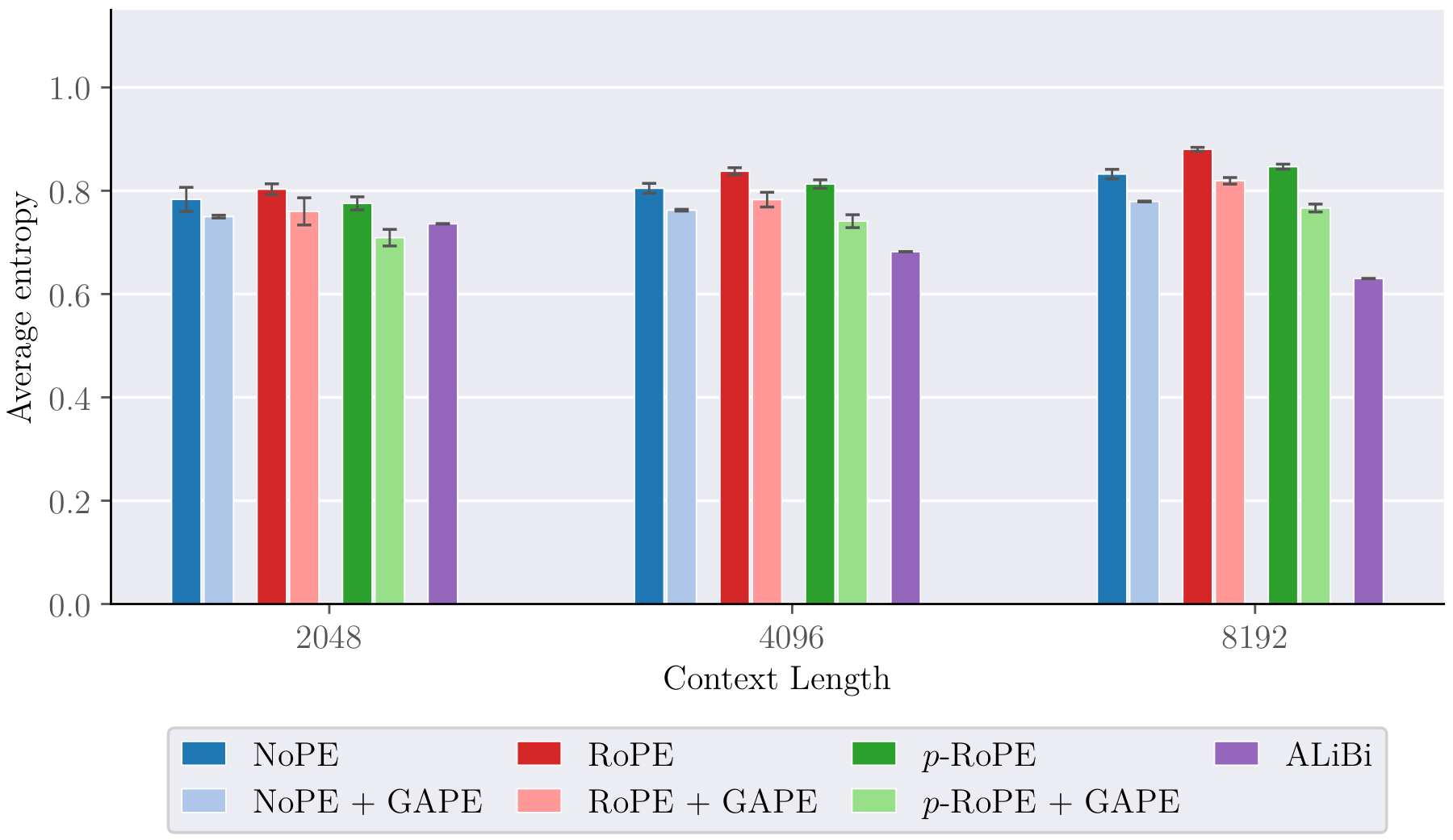
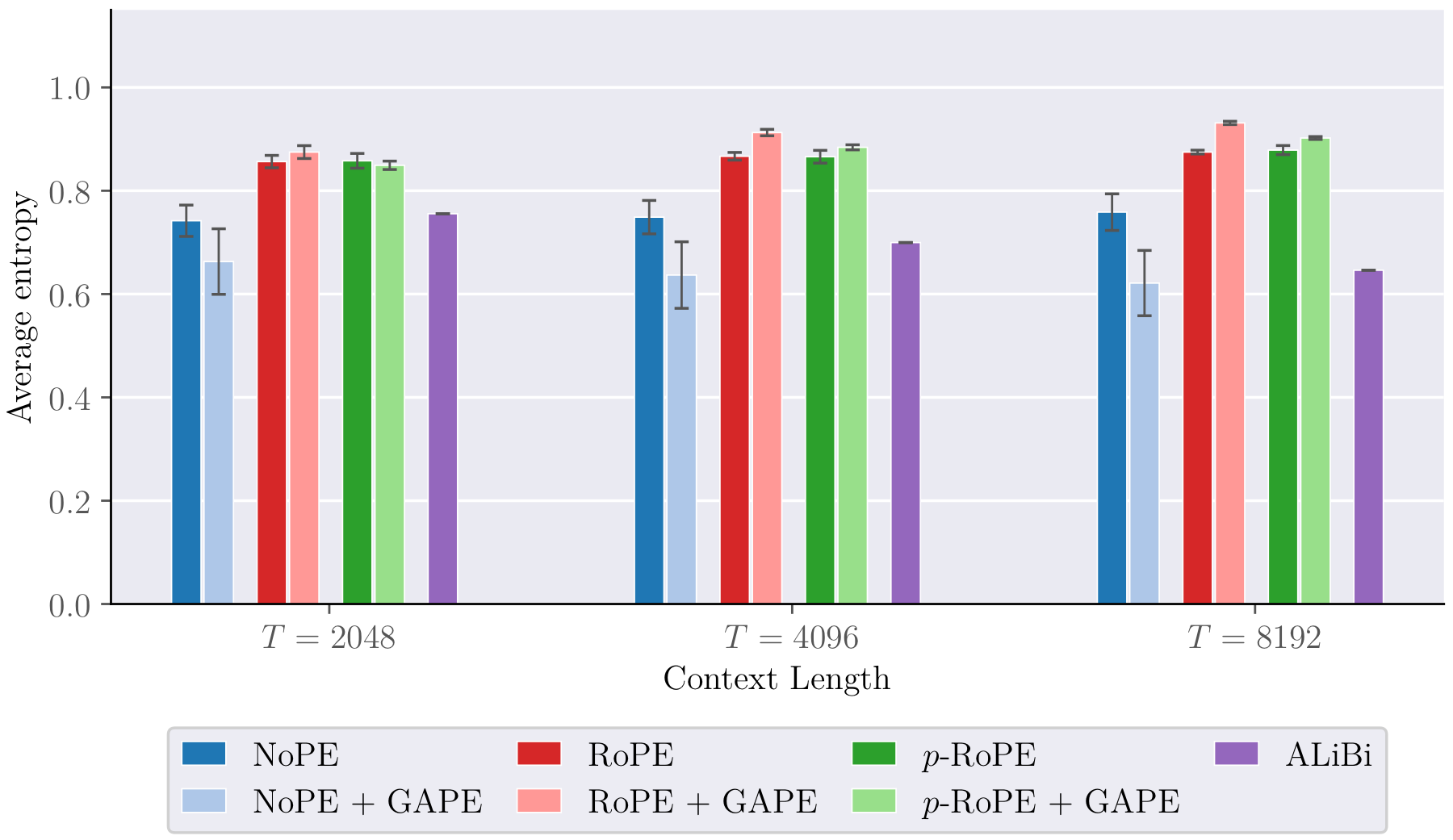
Attention Sharpness
The key gate’s mechanistic effect is visible directly in the attention maps: GAPE produces sharper, more focused attention patterns compared to the vanilla RoPE baseline.
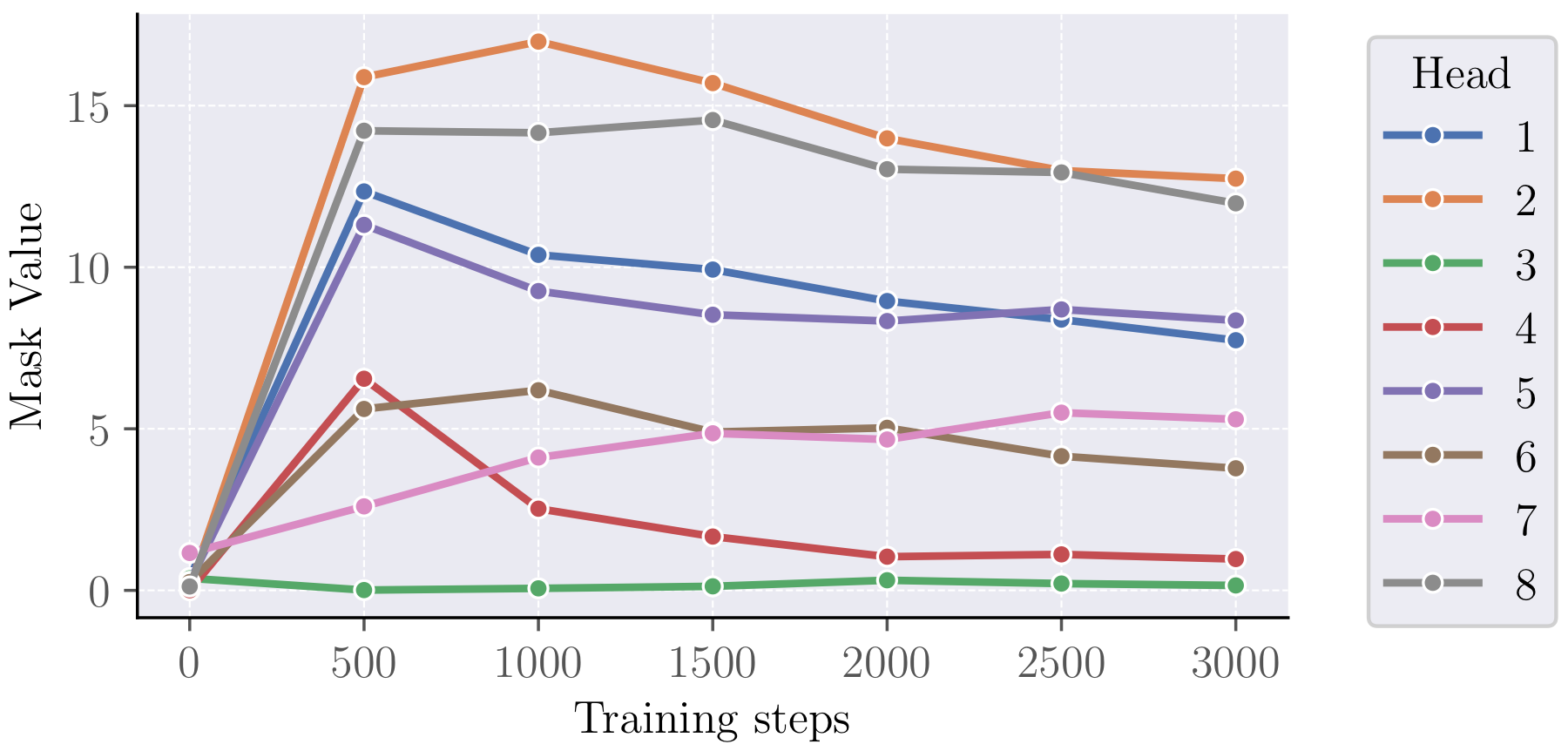
Gate Dynamics During Training
This part matters because GAPE is only useful if the gates learn a nontrivial routing policy rather than collapsing to a constant bias. The training dynamics show exactly that they do not collapse. Different heads and different layers settle into different regimes: some become strong suppressors of irrelevant background context, some remain relatively permissive, and some specialise in preserving a narrower set of salient positions.
In other words, the model is not learning one global “forget more” knob. It is learning a structured allocation of filtering behaviour across the attention stack. That is a much stronger result, because it suggests GAPE is expressive enough to adapt to the role of each head rather than merely acting as a blunt long-context penalty.

The next question is whether those learned gates actually change attention behaviour in the intended direction. The entropy plots answer that directly. If the gates are doing real work, attention should become sharper exactly in the layers where the model has learned stronger suppression of diffuse background context.
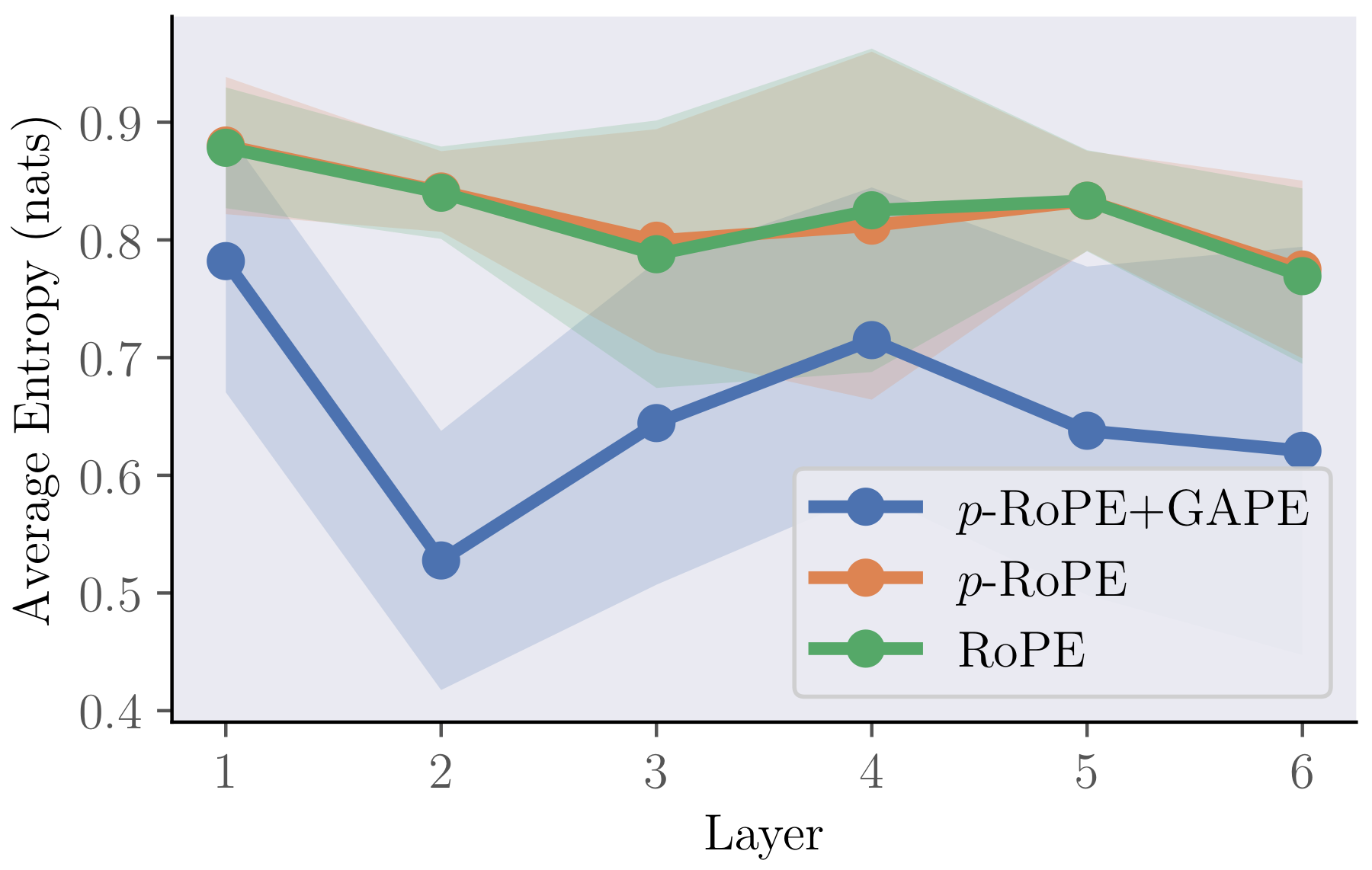
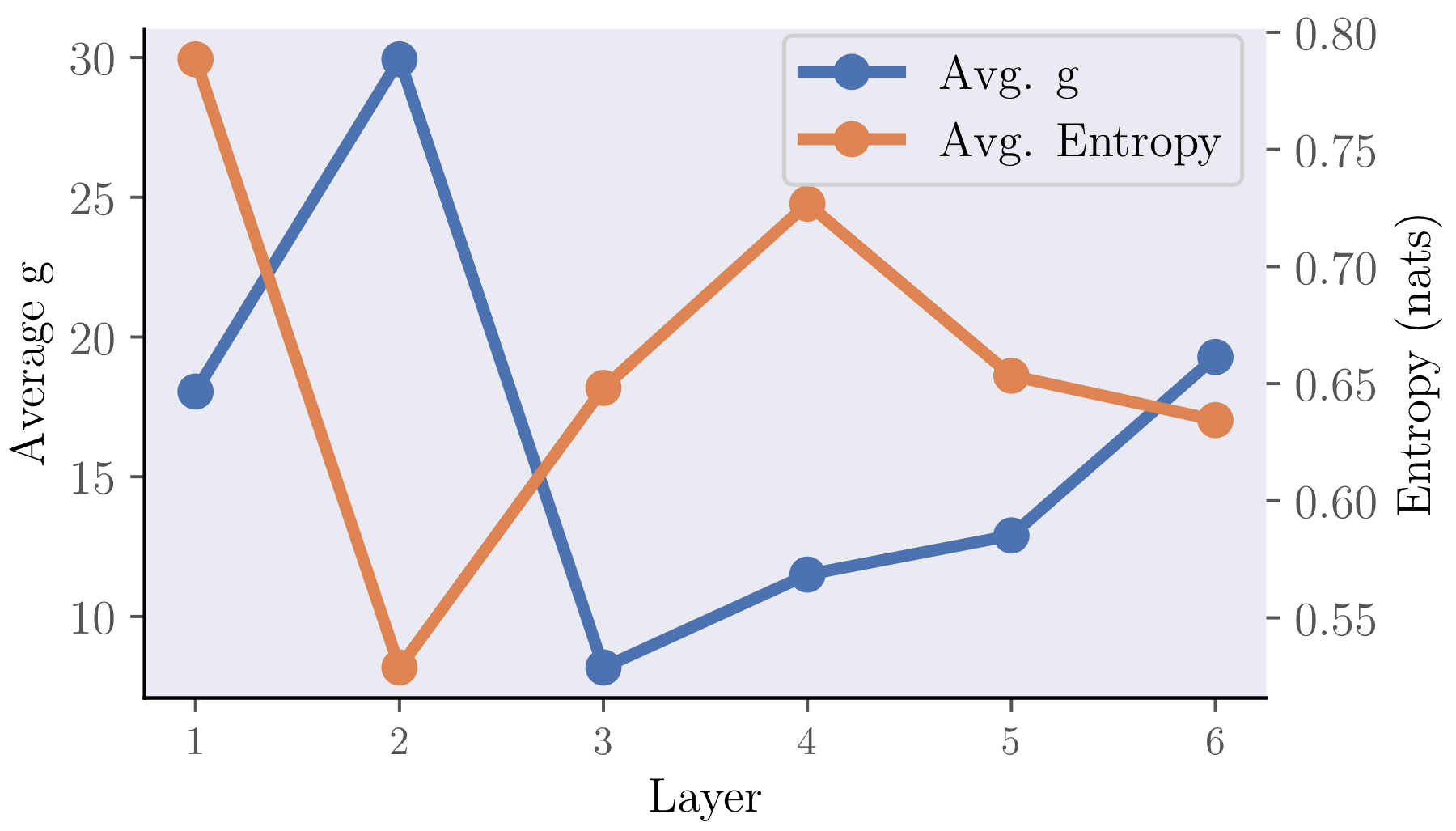
What makes the section convincing is the consistency between the mechanism variables and the downstream statistics. The learned gate magnitude is not floating independently of the attention maps; it tracks the same contraction effect that shows up in entropy. That is the kind of alignment you want from a mechanistic intervention: one variable that is interpretable, trainable, and visibly tied to the claimed behaviour.
Practical Interpretation
The cleanest way to think about GAPE is as an attention sharpener for long context. RoPE still provides the positional geometry. GAPE then decides, token by token, whether long-range attention should be damped or protected. That makes it a pragmatic drop-in modification rather than a replacement for the whole positional encoding stack.
✅ Key Takeaways
- GAPE adds a factored content-aware logit bias — query-gate × key-gate — that decouples "forgetting irrelevant context" from "protecting salient distant tokens".
- The rotary geometry of RoPE is completely preserved; GAPE is a drop-in augmentation requiring no architectural changes.
- Formal guarantee: protected tokens (high key-gate) remain accessible; unprotected distant tokens' attention mass decays with the query gate.
- Empirical gains on NIAH retrieval and long-context benchmarks at 1×, 2×, and 4× training context.