
RoPE: Rotary Position Embeddings
Published:

The Motivation
The ideal PE would:
- Inject absolute position information (so the model knows where each token is).
- Produce attention scores that depend only on relative distances (so the model generalises to longer sequences).
- Require no extra parameters.
Absolute PE achieves (1) but not (2). Relative PE achieves (2) but adds complexity. RoPE achieves all three simultaneously.
The Rotation Intuition
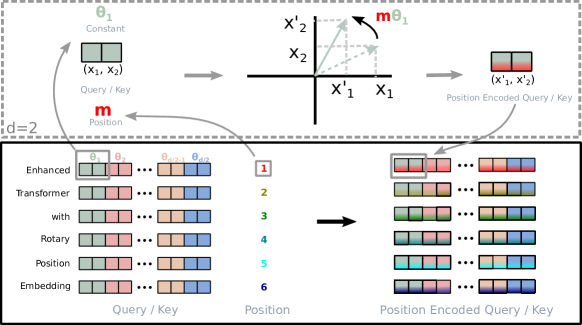
Think of each 2D pair of embedding dimensions as a 2D vector. Rotating it by an angle θ×position is like rotating a clock hand: the absolute angle encodes position, but two hands’ relative angle encodes their difference.
RoPE applies this idea to the entire d-dimensional embedding by treating it as d/2 pairs of 2D coordinates, each rotated by a different frequency.
The Math (Simplified)
For a 2D pair of embedding dimensions (x, y) at position pos:
This is just a standard 2D rotation matrix applied to (x, y) with angle θ × pos. For the full d-dimensional embedding, d/2 independent rotation matrices are applied — each pair at a different frequency (like sinusoidal PE).
The crucial identity: (R(m)·q) · (R(n)·k) = q · (R(n−m)·k) — the dot product depends only on n − m, the relative distance.
Concrete Worked Example (d = 2)
Let θ = π/6 (30°), and suppose query q = [1, 0] at position m = 1, key k = [1, 0] at position n = 3.
Rotate q by θ·m = 30°:
q_rot = [cos(30°), sin(30°)] = [0.866, 0.500]
Rotate k by θ·n = 90°:
k_rot = [cos(90°), sin(90°)] = [0.000, 1.000]
Dot product of rotated vectors:
q_rot · k_rot = 0.866 × 0 + 0.500 × 1 = 0.500
Verify the relative-distance identity: q · R(θ·(n−m)) · k = q · R(60°) · k
R(60°) · [1,0] = [cos60°, sin60°] = [0.500, 0.866]
[1,0] · [0.500, 0.866] = 0.500 ✓ (same result!)
The dot product only depended on the distance n−m = 2, not on the absolute positions 1 and 3. This is the key property that makes RoPE behave like a relative PE.
Why LLMs Love RoPE
Models using RoPE:
RoPE dominates modern LLM training because:
- No extra parameters — the rotation is computed on the fly.
- Relative attention from absolute encoding — the best of both worlds.
- Good extrapolation — with extensions like YaRN (Yet another RoPE extensioN), models trained on 4K tokens can serve 128K.
- Compatible with KV caching — rotations can be precomputed and cached efficiently.
RoPE Extensions for Long Context
Standard RoPE degrades when pushed far beyond training length. Several extensions fix this:
- Position Interpolation: scale positions down to fit training range.
- YaRN: different scaling for different frequency groups; currently the most popular approach.
LongRoPE / LongLLaMA: progressive context extension during fine-tuning.
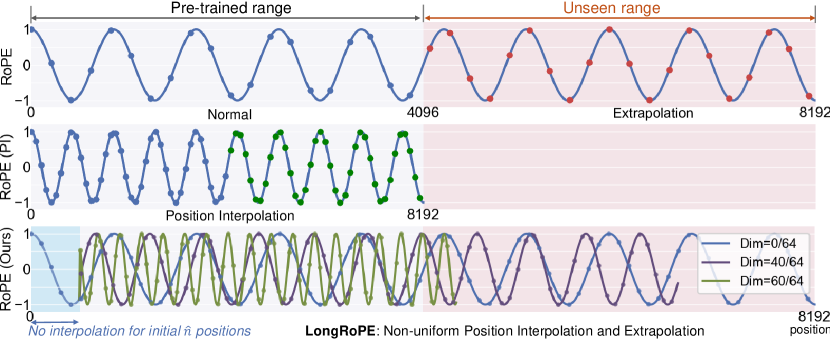
RoPE is the foundation; later methods such as LongRoPE extend it to much longer context windows by rescaling rotary frequencies more carefully (Ding et al., 2024).
References
- Su, J., et al. (2021). RoFormer: Enhanced Transformer with Rotary Position Embedding.
- Peng, B., et al. (2023). YaRN: Efficient Context Window Extension of Large Language Models.
- Ding, Y., et al. (2024). LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens.
✅ Key Takeaways
- RoPE rotates Q and K vectors by an angle proportional to position — no extra parameters.
- The dot product of rotated Q and K depends only on relative position, not absolute — the best of both worlds.
- Used in virtually every top-performing open-weight LLM: LLaMA 3, Mistral, Gemma.
- Extensions like YaRN enable far longer contexts than the training length.