
ALiBi: Attention with Linear Biases
Published:

The Simplest PE That Works
Press, Smith, and Lewis (2022) asked: do we even need position vectors? What if we just penalise attending to far-away tokens directly in the attention scores?
The idea: tokens that are far apart should pay a cost for attending to each other. Nearby tokens are cheap to attend to; distant ones are expensive.
They achieve this with a single number: a negative slope m per attention head.
The Formula
That’s it. The only change to standard attention is subtracting m × |i − j| from each score before the softmax. No PE vectors are added to embeddings at all.
Different attention heads use different slopes m, following a geometric sequence: {1/2, 1/4, 1/8, …, 2^(-h)} for h heads. Some heads focus locally (large m = steep penalty); others look further (small m = gentle penalty).
Concrete Worked Example (4 tokens, m = 0.5)
Suppose a query at position 2 attends to tokens at positions 0, 1, 2, 3. With slope m = 0.5 the raw attention score matrix row looks like:
Raw QK scores: [3.1, 4.5, 5.0, 3.8] (for tokens 0,1,2,3)
Distances |i−j|: [ 2, 1, 0, 1]
Bias (−m×dist): [−1.0, −0.5, 0.0, −0.5]
─────────────────────────
After bias: [2.1, 4.0, 5.0, 3.3]
Softmax: [0.04, 0.34, 0.56, 0.06]
Token 2 (self) still wins, but token 1 (distance 1) gets 34% attention. Token 0 (distance 2) is substantially penalised to just 4%. Now extend to a 100-token sequence: m × 98 = 49 for the farthest token. Very distant tokens are almost entirely penalised — local attention emerges naturally without any architectural change.
Why It Extrapolates
Standard PE trains on sequences of length L. Beyond L, the model has never seen those position indices and performance degrades.
ALiBi never uses position indices at all — only distances. At inference on a 4096-token sequence (when training was on 1024), the model sees distances like 1, 2, 3, … 4095 — but all it needs to do is subtract m × distance. The penalty formula works at any distance, so extrapolation is essentially free.
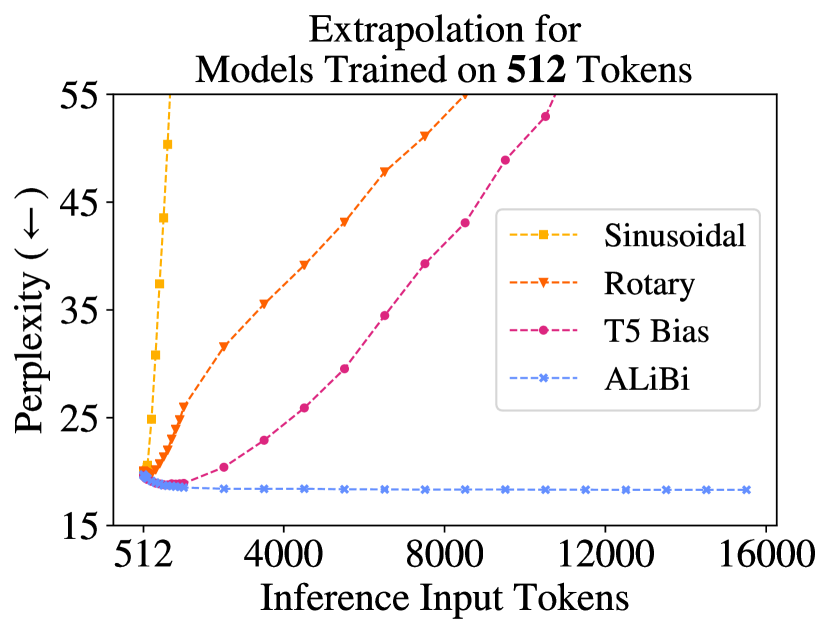
The paper reports that models trained at 1024 tokens with ALiBi outperform sinusoidal and learned PE baselines even at inference lengths of 2048 and 4096 tokens.
Trade-Offs
- Pro: Zero extra parameters, trivially simple.
- Pro: Excellent out-of-the-box extrapolation.
- Con: The linear bias is a strong inductive bias — locality is built in. Some tasks (e.g., cross-document retrieval) may prefer more flexible attention patterns.
- Con: Slightly outperformed by RoPE + YaRN in ultra-long-context regimes.
✅ Key Takeaways
- ALiBi adds no PE vectors — just subtracts
m × |i−j|from each attention score. - Different slopes m per head allow some heads to focus locally, others globally.
- Extrapolates to longer sequences than training because it only uses relative distance, never absolute position indices.
- Used in BLOOM (176B) and MPT; now somewhat superseded by RoPE + YaRN for long-context LLMs.