
RLHF: Reinforcement Learning from Human Feedback
Published:
The Alignment Problem for Language Models
A pre-trained large language model (LLM) is optimised to predict the next token, not to be helpful or follow instructions. The objective mismatch between pre-training (next-token prediction) and deployment (answering questions well, being safe) is the core challenge that RLHF addresses.
Human preferences encode what we actually want from a model — but they are difficult to specify as a mathematical reward function directly. RLHF learns a reward function from human comparative judgements, then optimises the LLM against it.
Step 1: Supervised Fine-Tuning (SFT)
Before RLHF, the base model is fine-tuned on a dataset of high-quality human-written demonstrations of desired behaviour (e.g., helpfully answering diverse prompts). This SFT model is the starting point for RLHF and provides a strong prior for the policy.
Step 2: Reward Model Training
Human labellers are shown pairs of model outputs \((y_1, y_2)\) for the same prompt \(x\) and indicate which they prefer. The reward model \(r_\phi\) is trained to assign higher scores to preferred outputs using the Bradley-Terry model:
where \(y_w\) is the preferred response and \(y_l\) the rejected one. The reward model is typically initialised from the SFT model with an additional scalar head replacing the final layer.
Step 3: PPO Fine-Tuning
The SFT model is fine-tuned with PPO to maximise the learned reward, subject to a KL divergence penalty against the original SFT model:
The KL penalty prevents reward hacking: without it, the policy rapidly finds ways to exploit the reward model’s weaknesses (generating grammatically unusual but highly rated outputs), collapsing coherence. The penalty keeps the policy close to the SFT distribution, preserving general capabilities while improving alignment.
PPO is used because: (1) the reward is provided by the reward model, not the environment, (2) the language generation is a long sequence of discrete actions (token selections), and (3) PPO’s clipping provides stable updates in this high-dimensional space.
InstructGPT and ChatGPT
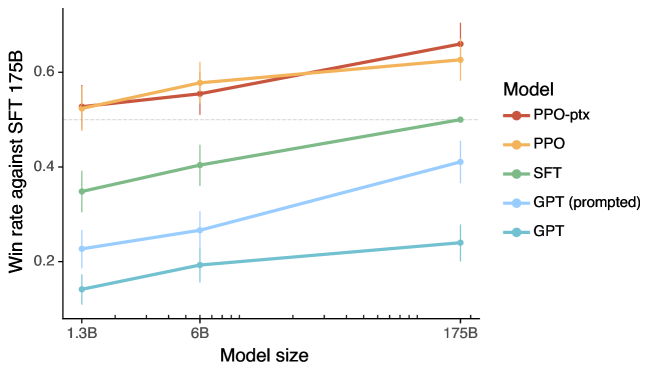
Ouyang et al. (2022) applied this pipeline to GPT-3, producing InstructGPT: labellers preferred InstructGPT outputs to GPT-3 outputs 85% of the time, despite InstructGPT being 100x smaller in parameter count. ChatGPT applied the same recipe to GPT-3.5, and GPT-4 was further aligned with RLHF, producing the foundation of modern conversational AI.
Constitutional AI and DPO
Constitutional AI (Bai et al. 2022, Anthropic) replaces human preference labels with AI-generated critiques following a set of constitutional principles, scaling the feedback process. DPO (Direct Preference Optimisation, Rafailov et al. 2023) eliminates the explicit reward model and PPO loop, directly optimising the LLM on preference data:
DPO is simpler and more stable than full RLHF, and has become a popular alternative for open-source model alignment.
References
- Christiano, P., Leike, J., Brown, T.B., Martic, M., Legg, S., & Amodei, D. (2017). Deep Reinforcement Learning from Human Preferences. NeurIPS. arXiv:1706.03741.
- Ouyang, L., Wu, J., Jiang, X., et al. (2022). Training language models to follow instructions with human feedback (InstructGPT). NeurIPS. arXiv:2203.02155.
- Bai, Y., Jones, A., Ndousse, K., et al. (2022). Constitutional AI: Harmlessness from AI Feedback. arXiv:2212.08073.
- Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C.D., & Finn, C. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model (DPO). NeurIPS. arXiv:2305.18290.