
RL for Games: From Atari to AlphaGo
Published:
Why Games?
Games provide uniquely clean environments for RL research: the reward signal is unambiguous, the environment is fast to simulate, and human-level performance provides a well-defined benchmark. Each new game environment has pushed the community to develop new techniques, from replay buffers and target networks (Atari), to Monte Carlo Tree Search with neural networks (board games), to population-based self-play and hierarchical architectures (real-time strategy).
DQN: Deep Q-Networks on Atari
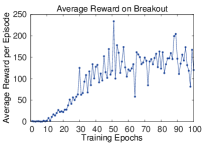
DQN (Mnih et al. 2015) was the first demonstration that a single deep RL algorithm could achieve human-level performance across a diverse suite of games. Two key innovations stabilised Q-learning with deep networks:
Experience replay: transitions \((s, a, r, s')\) are stored in a replay buffer and sampled i.i.d. for training, breaking temporal correlations.
Target network: a separate copy of the Q-network, updated every \(C\) steps, provides stable TD targets:
DQN achieved human-level or superhuman performance on 29 of 49 Atari games, using only raw pixels and the game score — the same information available to a human player.
AlphaGo: Mastering Go
Go was considered the holy grail of game AI: its branching factor (~250) and long-horizon dependencies made it intractable for traditional tree search. AlphaGo (Silver et al. 2016) combined:
- Supervised learning on human expert games to initialise the policy network.
- Policy gradient self-play to improve the policy beyond human level.
- MCTS guided by the policy network (for move selection) and a value network (for position evaluation).
AlphaZero: Tabula Rasa Self-Play
AlphaZero (Silver et al. 2017) removed all human knowledge from AlphaGo: no expert data, no handcrafted features, no separate policy and value networks. A single network with shared weights predicts both policy and value:
Training is entirely self-play: MCTS with the current network generates training data, and gradient descent on the resulting (policy target, value target) pairs improves the network. AlphaZero surpassed AlphaGo, Stockfish (Chess), and Elmo (Shogi) — all from scratch, in hours of training.
AlphaStar: StarCraft II
StarCraft II presents challenges beyond board games: real-time decision-making, imperfect information (fog of war), a vast action space (~\(10^{26}\) possible actions), and long episodes (hours of real time). AlphaStar (Vinyals et al. 2019) tackled these with:
- A transformer-based architecture over units and map features.
- A pointer network for selecting units from a variable-length list.
- A multi-agent self-play league (Main agents, League Exploiters, Main Exploiters) to avoid strategy collapse.
- Supervised pre-training on human replays.
AlphaStar reached Grandmaster level, surpassing 99.8% of human players on the European ladder.
OpenAI Five: Dota 2
OpenAI Five (Berner et al. 2019) trained five PPO agents on Dota 2 — a cooperative multi-player game with a 45-minute horizon and 10,000+ possible actions per step. Using 128,000 CPU cores generating 900 years of self-play per day, OpenAI Five defeated the Dota 2 world champions in April 2019.
The Broader Impact
Each of these achievements drove methodological advances: replay buffers and target networks (DQN), policy gradient + MCTS fusion (AlphaGo), tabula rasa self-play (AlphaZero), multi-agent leagues (AlphaStar), and massively parallel PPO at scale (OpenAI Five). The game-playing successes have directly transferred to scientific domains: AlphaFold (protein structure), AlphaDev (compiler optimisation), and AlphaMath (mathematical reasoning).
References
- Mnih, V., Kavukcuoglu, K., Silver, D., et al. (2015). Human-level control through deep reinforcement learning. Nature, 518, 529–533.
- Silver, D., Huang, A., Maddison, C.J., et al. (2016). Mastering the game of Go with deep neural networks and tree search (AlphaGo). Nature, 529, 484–489.
- Silver, D., Schrittwieser, J., Simonyan, K., et al. (2017). Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm (AlphaZero). arXiv:1712.01815.
- Vinyals, O., Babuschkin, I., Czarnecki, W.M., et al. (2019). Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 575, 350–354.
- Berner, C., Brockman, G., Chan, B., et al. (2019). Dota 2 with Large Scale Deep Reinforcement Learning (OpenAI Five). arXiv:1912.06680.