
RL for Robotics: From Simulation to Real Hardware
Published:
The Robotics Challenge
Robotics is one of the most demanding application domains for RL. The challenges are qualitatively different from games:
- Sample inefficiency: a physical robot runs at real time; collecting millions of interactions takes months.
- Hardware safety: a bad policy can damage the robot, the environment, or nearby humans.
- Sim-to-real gap: physical dynamics are complex and not fully captured by simulation.
- Sparse rewards: “did the robot grasp the object?” returns a reward only upon success, with no gradient signal during the attempt.
- Partial observability: robots perceive the world through noisy sensors, not perfect state.
Simulation and the Sim-to-Real Gap
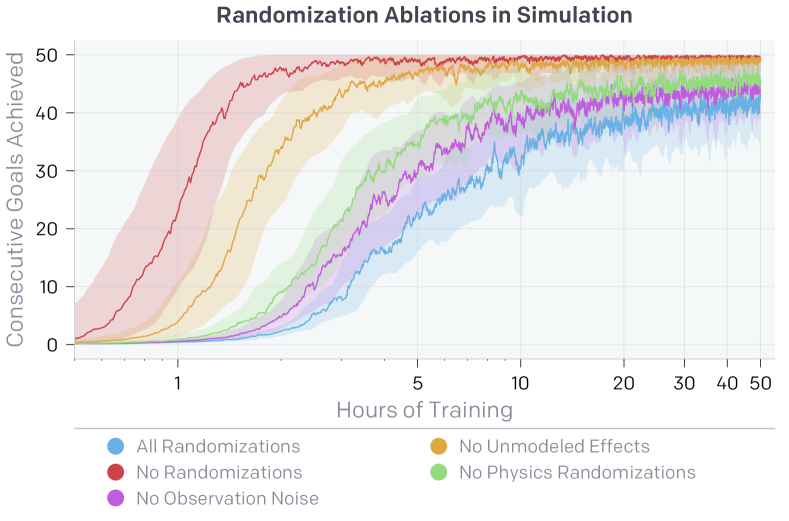
Training in simulation avoids hardware wear and enables parallelism: 1,000 simulated robots training simultaneously in MuJoCo or Isaac Gym generates data orders of magnitude faster than a real robot. However, the sim-to-real gap — differences in friction, actuator dynamics, sensor noise, and visual appearance — can cause policies trained in simulation to fail when deployed on real hardware.
Domain randomisation (Tobin et al. 2017; Andrychowicz et al. 2019) addresses this by randomising simulation parameters during training:
where \(\xi\) captures randomised parameters (mass, friction, damping, motor delays, visual textures). If the range of randomisation spans the real world, the policy must generalise across all of them — and real hardware is just one more point in the distribution.
OpenAI Dactyl: Dexterous Manipulation
OpenAI Dactyl (Andrychowicz et al. 2019) trained a Shadow Dexterous Hand to solve a Rubik’s cube — a task requiring 24 degrees of freedom and fine-grained finger coordination. The training used:
- 13,000+ CPU cores running MuJoCo in parallel.
- Automatic Domain Randomisation (ADR): the randomisation range expands automatically whenever the policy becomes proficient at the current range.
- PPO with LSTM to handle the history of partially observed states.
The policy successfully solved the Rubik’s cube on real hardware, demonstrating that extreme dexterity can emerge from sim-to-real transfer.
MuJoCo Locomotion
MuJoCo (Multi-Joint dynamics with Contact) has become the standard benchmark for continuous control. Tasks like HalfCheetah, Ant, Hopper, and Humanoid require learning smooth, stable gaits through high-dimensional action spaces (up to 21 joints). These tasks test the raw optimisation power of policy gradient methods:
Reward shaping terms — forward velocity, action cost, healthy posture bonuses — guide exploration when task completion alone is too sparse. SAC and PPO have both achieved human-quality gaits on these benchmarks.
Reward Shaping and Sparse Rewards
Sparse rewards make exploration extremely difficult: the robot receives no learning signal until it stumbles upon success by chance. Reward shaping adds dense intermediate signals:
- Potential-based shaping (Ng et al. 1999): adding \(F(s, s') = \gamma \Phi(s') - \Phi(s)\) for a potential function \(\Phi\) preserves the optimal policy while densifying the reward.
- Hindsight Experience Replay (HER): relabels failed trajectories as successes for different goal states, converting failures into training signal.
Safety Constraints in RL
Safe RL formalises constraints as a Constrained MDP:
where \(C^i\) is the expected cumulative cost of constraint \(i\). Methods like Constrained Policy Optimisation (CPO) and Safety-Gym provide frameworks for learning policies that satisfy hard safety limits — essential for deploying robots near humans.
References
- Andrychowicz, O.M., Baker, B., Chociej, M., et al. (2020). Learning dexterous in-hand manipulation (OpenAI Dactyl). International Journal of Robotics Research, 39(1), 3–20. arXiv:1808.00177.
- Tobin, J., Fong, R., Ray, A., Schneider, J., Zaremba, W., & Abbeel, P. (2017). Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World. IROS.
- Ng, A.Y., Harada, D., & Russell, S.J. (1999). Policy Invariance Under Reward Transformations: Theory and Application to Reward Shaping. ICML.
- Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347.
- Achiam, J., Held, D., Tamar, A., & Abbeel, P. (2017). Constrained Policy Optimization. ICML. arXiv:1705.10528.