
Multi-Agent Reinforcement Learning
Published:
The Multi-Agent Setting
In a multi-agent environment, \(N\) agents simultaneously take actions \(a^1, \ldots, a^N\) in a shared state \(s\), receiving rewards \(r^1, \ldots, r^N\). Depending on the reward structure:
- Cooperative: all agents share a common reward — maximise team performance.
- Competitive (zero-sum): one agent’s gain is another’s loss — find a Nash equilibrium.
- Mixed: agents cooperate partially and compete partially (e.g., team sports).
The Markov Game framework (Littman 1994) generalises MDPs to multiple agents:
where \(T(s' \mid s, a^1, \ldots, a^N)\) is the joint transition and each \(R^i\) is agent \(i\)’s reward function.
The Non-Stationarity Problem
The central challenge in MARL is non-stationarity: from agent \(i\)’s perspective, the environment is non-Markovian because other agents’ policies are changing during training. Standard convergence guarantees for single-agent RL do not apply.
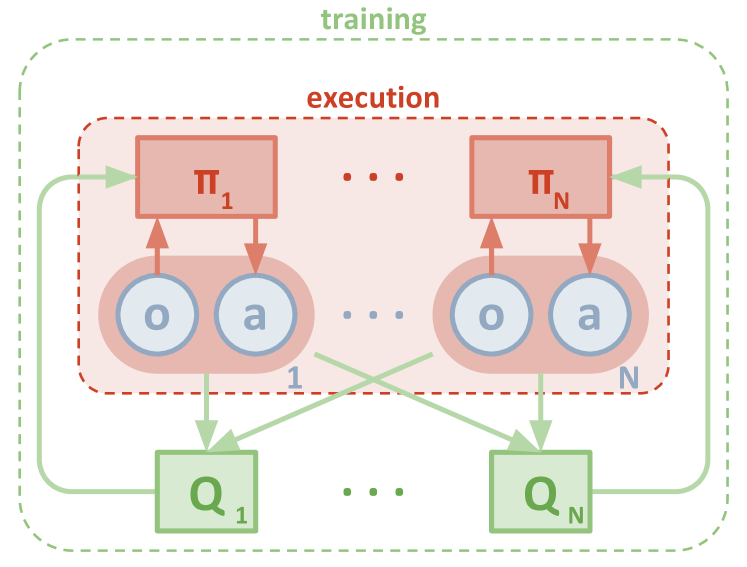
Centralised Training with Decentralised Execution (CTDE)
The CTDE paradigm resolves the tension between:
- Training: access to global information (all agents’ observations, actions, communications) makes learning stable.
- Execution: each agent must act using only its local observations (partial observability, communication constraints).
CTDE methods train a centralised critic that uses global information, while each agent’s policy only conditions on local observations.
MADDPG: Multi-Agent DDPG
MADDPG (Lowe et al. 2017) extends DDPG to the multi-agent setting under CTDE. Each agent \(i\) has:
- A decentralised actor \(\pi_i(a^i \mid o^i)\) — conditioned only on agent \(i\)’s local observation.
- A centralised critic \(Q_i(o^1,...,o^N, a^1,...,a^N)\) — takes all observations and actions.
By conditioning the critic on all agents’ actions, MADDPG handles the non-stationarity: from the critic’s perspective, the environment is stationary given all agents’ actions.
QMIX: Monotonic Value Decomposition
QMIX (Rashid et al. 2018) addresses cooperative MARL by decomposing the joint action-value function into per-agent utilities via a monotonic mixing network:
The mixing network has positive weights (enforced by absolute value activations), guaranteeing that:
This factorisation means each agent can greedily maximise its individual utility and the result is globally optimal — dramatically simplifying decentralised execution.
Nash Equilibria in Competitive Settings
In zero-sum games, the appropriate solution concept is a Nash equilibrium: a joint policy \(({\pi^*}^1, \ldots, {\pi^*}^N)\) such that no agent can improve by unilaterally deviating. Computing Nash equilibria is PPAD-hard in general, but self-play (each agent trains against the other) empirically converges to strong policies in many games. AlphaZero and OpenAI Five exploit this principle.
References
- Lowe, R., Wu, Y., Tamar, A., Harb, J., Abbeel, P., & Mordatch, I. (2017). Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments (MADDPG). NeurIPS. arXiv:1706.02275.
- Rashid, T., Samvelyan, M., Schroeder, C., Farquhar, G., Foerster, J., & Whiteson, S. (2018). QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning. ICML. arXiv:1803.11605.
- Littman, M.L. (1994). Markov Games as a Framework for Multi-Agent Reinforcement Learning. ICML.
- Oliehoek, F.A., & Amato, C. (2016). A Concise Introduction to Decentralized POMDPs. Springer.
- Foerster, J., Farquhar, G., Afouras, T., Nardelli, N., & Whiteson, S. (2018). Counterfactual Multi-Agent Policy Gradients (COMA). AAAI. arXiv:1705.08926.