
A3C: Asynchronous Advantage Actor-Critic
Published:
Motivation: The Problem with Replay Buffers
Deep Q-Networks stabilise training by replaying past transitions sampled i.i.d. from a large buffer, breaking the temporal correlations that destabilise stochastic gradient descent. The replay buffer, however, comes with costs: it stores only off-policy data, requires off-policy corrections for policy gradient methods, and demands significant memory.
A3C (Mnih et al. 2016) proposes a different decorrelation strategy: run many independent agents simultaneously. Because different workers are at different points in the environment at any given time, their gradients are naturally decorrelated, making on-policy learning stable without a replay buffer.
Actor-Critic Architecture
Actor-critic methods maintain two components:
- Actor: the policy \(\pi_\theta(a \mid s)\) — selects actions.
- Critic: the value function \(V_\phi(s)\) — estimates expected return from state \(s\).
The critic’s estimate serves as a baseline, yielding the advantage:
This is the TD error, a one-step estimate of the advantage. Using the advantage instead of raw returns reduces variance substantially while introducing only modest bias from the bootstrap.
The Advantage Function
The n-step return generalises the one-step TD error:
Larger \(n\) reduces bias at the cost of higher variance. A3C typically uses \(n = 5\) steps, balancing this trade-off effectively.
Asynchronous Parallel Workers
The asynchronous architecture is deceptively simple:
- A global network holds the shared parameters \((\theta, \phi)\).
- Each worker thread copies the global parameters to its local network.
- The worker runs \(n\) steps, accumulates policy and value gradients.
- The worker applies its gradients asynchronously to the global network (using RMSprop without locking).
- Repeat.
Because workers push gradients without locking, updates can be slightly stale — a worker may apply gradients computed with parameters that are a few steps behind the global network. Empirically this staleness is benign and does not harm convergence.
The combined loss optimised by each worker is:
where \(L_\text{policy} = -\log \pi_\theta(a_t \mid s_t) \cdot A_t\), \(L_\text{value} = (G_t - V_\phi(s_t))^2\), and \(H[\pi_\theta]\) is an entropy bonus that encourages exploration.
A2C: The Synchronous Variant
A2C (Advantage Actor-Critic) is a synchronous version of A3C: a central coordinator waits for all workers to finish their \(n\)-step rollouts, then performs a single update. This makes the algorithm deterministic and easier to reproduce. In practice A2C matches or exceeds A3C on GPU hardware, because synchronous batching makes better use of vectorised computation.
Results and Significance
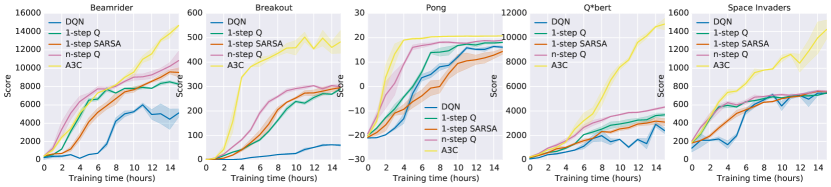
A3C achieved human-level or superhuman performance on 57 Atari games, matching DQN with far less training time. On a 16-core CPU without any GPU, A3C trained in hours rather than days. The work demonstrated that parallelism — not just replay — is a valid and efficient stabilisation strategy, opening the door to on-policy deep RL at scale.
References
- Mnih, V., Badia, A.P., Mirza, M., Graves, A., Lillicrap, T.P., Harley, T., Silver, D., & Kavukcuoglu, K. (2016). Asynchronous Methods for Deep Reinforcement Learning. ICML. arXiv:1602.01783.
- Mnih, V., Kavukcuoglu, K., Silver, D., et al. (2015). Human-level control through deep reinforcement learning. Nature, 518, 529–533.
- Sutton, R.S., & Barto, A.G. (2018). Reinforcement Learning: An Introduction (2nd ed.). MIT Press. Chapters 9, 13.
- Wu, Y., Mansimov, E., Liao, S., Grosse, R., & Ba, J. (2017). Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation. NeurIPS. arXiv:1708.05144.