
Message Passing: The Universal GNN Framework
Published:
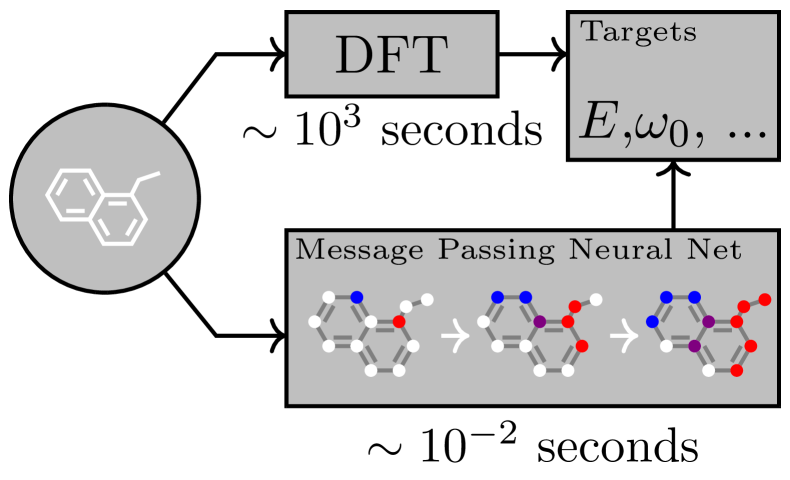
The Framework
The MPNN framework (Gilmer et al., 2017, NeurIPS) defines GNN computation through a series of message passing steps. At each step t:
ht+1v = UPDATE(htv, mt+1v)
Where:
h^t_v— representation of node v at step t.N(v)— neighbours of v.e_{uv}— optional edge feature between u and v.MSG— the message function.AGGREGATE— combines all messages (must be permutation-invariant).UPDATE— computes new representation from old + aggregated message.
Concrete Worked Example: One Full MPNN Step
Let node B have features h_B = [1, 0], with three neighbours:
- A: h_A = [0, 1]
- C: h_C = [1, 1]
- D: h_D = [0, 0]
Step 1 — Compute messages (using identity MSG, i.e. just pass neighbour features):
msg(A→B) = [0, 1]
msg(C→B) = [1, 1]
msg(D→B) = [0, 0]
Step 2 — Aggregate (sum):
agg_B = [0,1] + [1,1] + [0,0] = [1, 2]
Step 3 — Update (concatenate own features + aggregated, apply linear W):
input = concat(h_B, agg_B) = [1, 0, 1, 2]
h_B_new = ReLU( W · [1, 0, 1, 2] ) # W is 2×4 learned weight matrix
After this one layer, B’s new 2-d embedding encodes information from all three of its neighbours.
Step 1: Message Function
The message function computes what each neighbour sends. The simplest choice: just send the neighbour’s features.
MSG(h_v, h_u, e_uv) = h_u # GCN: just pass neighbour features
MSG(h_v, h_u, e_uv) = W · h_u # Linear transform first
MSG(h_v, h_u, e_uv) = α · W · h_u # GAT: scale by attention weight
Including edge features allows the model to distinguish bond types in a molecule or relationship types in a knowledge graph.
Step 2: Aggregate Function
The aggregation combines all messages. It must be permutation-invariant (the order of neighbours shouldn’t matter):
| Aggregator | Formula | Properties | ||
|---|---|---|---|---|
| Sum | Σ m_u | Captures size of neighbourhood | ||
| Mean | (1/ | N | ) Σ m_u | Normalised, size-invariant |
| Max | max_u m_u | Captures the most extreme feature | ||
| Attention-weighted | Σ α_u m_u | Adaptive, like GAT |
GIN (see separate post) proves that sum is the most powerful aggregator for distinguishing graph structures. Mean and max lose information.
Step 3: Update Function
Given the aggregated message and the old representation, compute the new one:
h_v^new = σ(W · concat(h_v, agg_message)) # GCN-style
h_v^new = GRU(h_v, agg_message) # Recurrent update
h_v^new = MLP(concat(h_v, agg_message)) # GraphSAGE-style
A Running Example: Molecule Property Prediction
Consider predicting if a molecule is toxic:
- Nodes = atoms (features: atom type, charge, is_aromatic)
- Edges = bonds (features: bond type: single/double/triple)
- After k MPNN layers, each atom knows about its k-hop neighbourhood.
- A readout aggregates all atom embeddings into a graph embedding.
- An MLP predicts toxicity from the graph embedding.
After 3 layers, an atom “knows” about the atoms 3 bonds away — capturing local chemical environments like functional groups.
✅ Key Takeaways
- All GNNs are instances of MPNN: choose MSG, AGGREGATE, and UPDATE functions.
- AGGREGATE must be permutation-invariant. Sum is the most expressive choice (GIN).
- After k layers, each node's embedding captures its k-hop neighbourhood.
- Graph-level predictions require a readout function that pools node embeddings into a single vector.
References
- Hamilton, W. L. (2020). Graph Representation Learning. Synthesis Lectures on Artificial Intelligence and Machine Learning.
- Gilmer, J., Schoenholz, S. S., Riley, P. F., Vinyals, O., & Dahl, G. E. (2017). Neural Message Passing for Quantum Chemistry. ICML 2017.