
Query, Key, Value: The Intuition Behind QKV
Published:
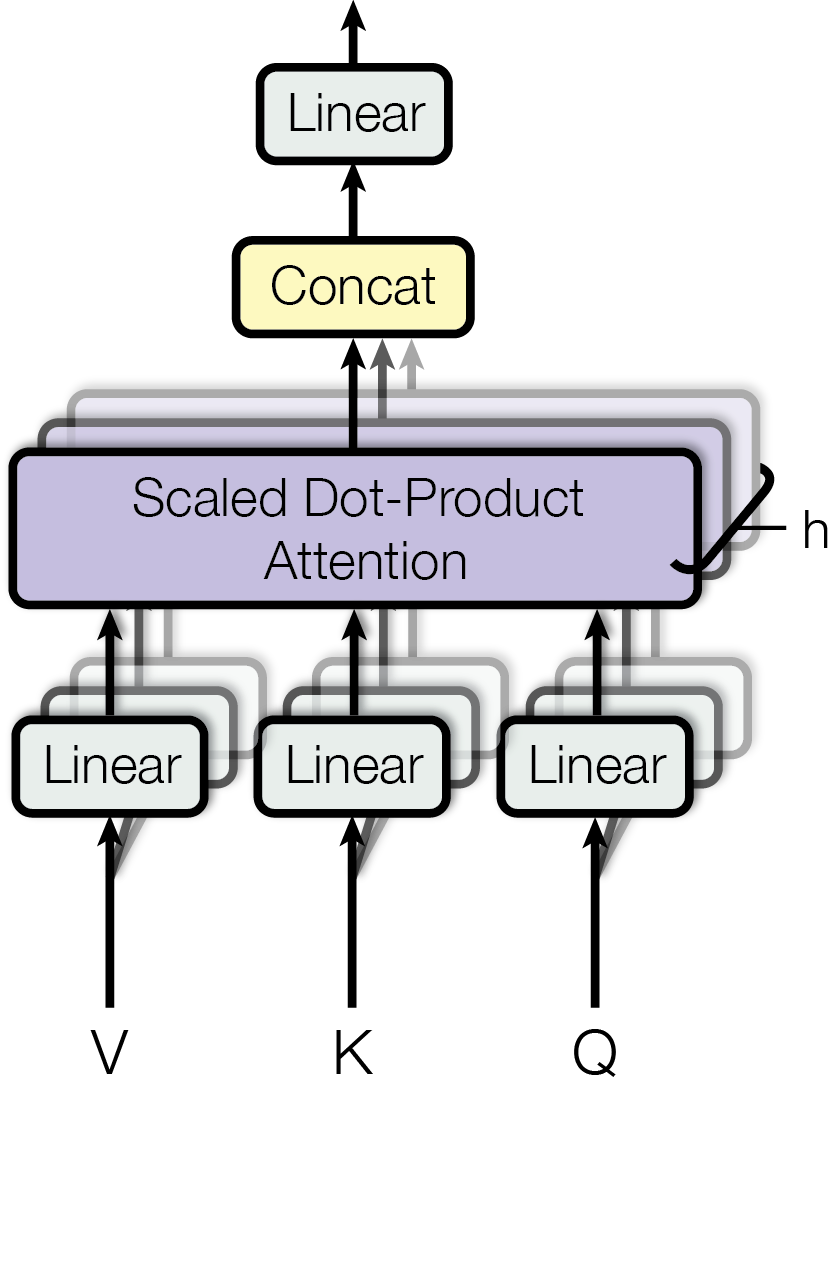
The Analogy: A Smart Library
Imagine walking into a library with a question: “I want something about neural networks.”
- Query (Q): your question — what you’re searching for
- Key (K): the labels on every book’s spine — what each book is about
- Value (V): the actual content of each book — what you retrieve when you pick one up
You compare your question (Q) against every spine label (K). The closer the match, the more of that book’s content (V) you retrieve. If three books are slightly relevant and one is very relevant, you blend them proportionally.
This is exactly what attention does — but over tokens in a sequence, and with vectors instead of text labels.
In Transformer Notation
Each token in the input sequence gets three vector representations learned by the model:
Where X is the token representation and W_Q, W_K, W_V are learned weight matrices. The model learns what to advertise (K), what to ask for (Q), and what to share (V) — and these can be different projections of the same token.
A Token’s Three Faces
Consider the word “bank” in the sentence “The bank approved the loan.”
When “bank” is being asked about (as a key):
- It advertises: I’m a financial institution
When “bank” is asking questions (as a query):
- It might ask: What other financial terms are nearby?
When “bank” contributes information (as a value):
- It provides: its full contextual representation, to be mixed into other tokens’ outputs
A single token plays all three roles simultaneously — as a key for others querying it, as a query seeking information from others, and as a value supplying its content when called.
Why Not Just Use One Matrix?
A natural question: why not compute similarity directly between token representations, without Q, K, V projections?
Two reasons:
1. Asymmetry. The question you ask (Q) and the label you advertise (K) can be different things. The word “bank” might advertise its financial meaning but query for loan-related terms. A single representation forces them to be the same — which is too restrictive.
2. Information compression. The value (V) can be a different, richer projection than the key (K). Keys are optimised for matching; values are optimised for being informative. Separating them lets the model decouple finding information from extracting it.
Worked Example: The Word “Bank”
Consider the sentence: “The bank approved the loan.”
During a forward pass, “bank” generates three vectors:
| Vector | Learned to… | Example content |
|---|---|---|
| k (Key) | Advertise: I am a financial institution | high overlap with “finance”, “money” keys |
| q (Query) | Ask: what financial terms are nearby? | high score against “loan”, “approved” keys |
| v (Value) | Contribute: rich contextual embedding | full d_model representation with context |
Now “loan” (another token) has a Query asking “who approved me?”. Its q scores highly against “bank”’s k. So “loan”’s output mixes in a lot of “bank”’s v — gaining knowledge that its approver is a financial institution.
Notice: “bank”’s k just needs to be good at being found. Its v can carry far more information. Separating them lets the model optimise these two functions independently.
The Most Common Beginner Confusion
A lot of people think V is just “K later in the pipeline.” It is not. K is optimised to be matched against queries; V is optimised to carry useful information once a match has been found.
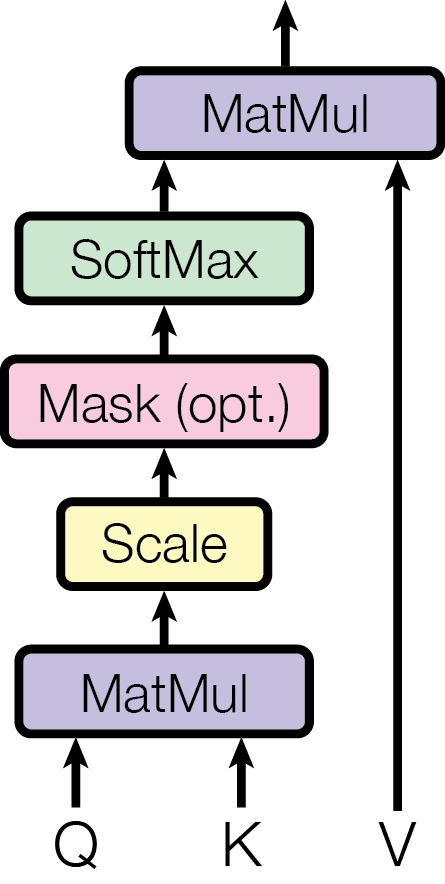
The Full Attention Computation Step by Step
Given a single query token and a sequence of key-value pairs:
- Match: compute q · kᵢ for every token i → raw similarity scores
- Scale: divide by √d_k → prevent softmax saturation
- Normalise: softmax → convert scores to a probability distribution (attention weights)
- Retrieve: weighted sum of values → the output for this query token
The result is a blend of all value vectors, weighted by how much each token’s key matched the query. Tokens with high relevance contribute more; irrelevant tokens contribute near zero.
The Analogy Revisited: A Database
| Database concept | Attention equivalent |
|---|---|
| Search query | Query vector q |
| Index keys | Key vectors k₁…kₙ |
| Retrieved records | Value vectors v₁…vₙ |
| Exact match (hard) | Argmax over scores |
| Fuzzy match (soft) | Softmax-weighted blend |
Classic databases return one result (hard lookup). Attention returns a differentiable weighted blend — which means gradients can flow through it and the whole system can be trained end-to-end.
Summary
| Symbol | What it is | What it does |
|---|---|---|
| Q | Query | What this token is looking for |
| K | Key | What each token advertises it contains |
| V | Value | What each token contributes when selected |
| QKᵀ | Similarity | How well query matches each key |
| Softmax | Normalisation | Converts similarities to weights |
| Weighted V | Output | Blend of values, weighted by attention |
QKV is a learned, differentiable, soft database lookup. Once you see it this way, the rest of the Transformer follows naturally.
References
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. NeurIPS 2017 (source of the QKV formulation: W_Q, W_K, W_V projection matrices for scaled dot-product attention).
- Elhage, N., Nanda, N., Olsson, C., Henighan, T., et al. (2021). A Mathematical Framework for Transformer Circuits. Anthropic 2021 (mechanistic interpretability analysis of how QKV matrices implement composition and information routing in Transformers).