
Attention Masks: Causal, Padding, and Bidirectional
Published:
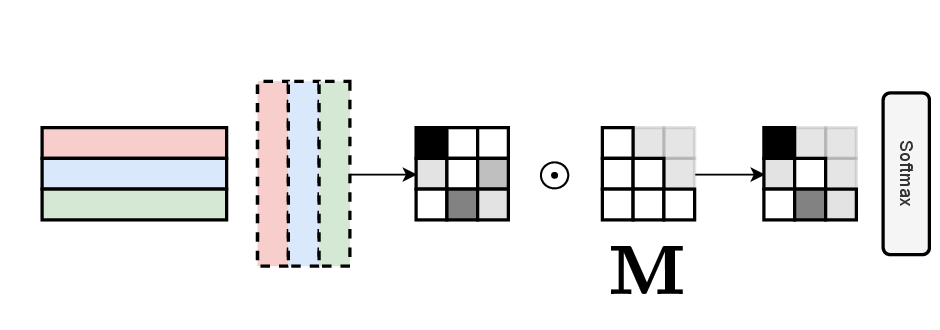
Why Masks Exist
Raw scaled dot-product attention lets every token attend to every other token. Sometimes that is exactly what you want. But often you need to restrict this:
- Language modelling: token 5 must not see token 6 — that would be cheating during training
- Batching: sentences padded to equal length should not attend to the padding
- Encoder-decoder: the decoder needs restricted attention but the encoder does not
Masks solve all of these. They are applied to the raw attention scores before softmax — typically by adding −∞ to masked positions, which softmax converts to 0 weight.
1. Bidirectional Mask (BERT-style)
A bidirectional mask places no restrictions. Every token can attend to every other token, including itself.
The cat sat on the mat
The [ ✓ ✓ ✓ ✓ ✓ ✓ ]
cat [ ✓ ✓ ✓ ✓ ✓ ✓ ]
sat [ ✓ ✓ ✓ ✓ ✓ ✓ ]
on [ ✓ ✓ ✓ ✓ ✓ ✓ ]
the [ ✓ ✓ ✓ ✓ ✓ ✓ ]
mat [ ✓ ✓ ✓ ✓ ✓ ✓ ]
Every cell is open. Each token’s representation is built from the entire sequence simultaneously.
Used by: BERT, RoBERTa, DeBERTa, any encoder-only model.
Good for: classification, NER, question answering — tasks where you read the whole input before deciding.
Cannot do: autoregressive generation — you cannot generate token 6 if token 5 already sees token 6.
2. Causal Mask (GPT-style)
A causal (autoregressive) mask enforces that token i can only attend to tokens ≤ i. The future is blocked.
The cat sat on the mat
The [ ✓ ✗ ✗ ✗ ✗ ✗ ]
cat [ ✓ ✓ ✗ ✗ ✗ ✗ ]
sat [ ✓ ✓ ✓ ✗ ✗ ✗ ]
on [ ✓ ✓ ✓ ✓ ✗ ✗ ]
the [ ✓ ✓ ✓ ✓ ✓ ✗ ]
mat [ ✓ ✓ ✓ ✓ ✓ ✓ ]
The attention matrix is lower-triangular. The diagonal is always visible (self-attention). Everything above the diagonal is −∞.
Used by: GPT, GPT-2, GPT-3, GPT-4, LLaMA, Mistral, all decoder-only models.
Good for: language generation — at each step, the model predicts the next token from all previous tokens.
Key property: during training, all positions can be processed in parallel (the mask handles causality). During inference, tokens are generated one at a time.
3. Padding Mask
When batching sequences of different lengths, shorter sequences are padded to the maximum length in the batch. Padding tokens carry no meaningful information and should not influence attention.
Sentence A: "The cat sat" [PAD] [PAD]
Sentence B: "Go" [PAD] [PAD] [PAD]
The padding mask blocks attention to [PAD] positions:
The cat sat PAD PAD
The [ ✓ ✓ ✓ ✗ ✗ ]
cat [ ✓ ✓ ✓ ✗ ✗ ]
sat [ ✓ ✓ ✓ ✗ ✗ ]
PAD [ ✗ ✗ ✗ ✗ ✗ ]
PAD [ ✗ ✗ ✗ ✗ ✗ ]
Padding masks are applied on top of whatever other mask is in use. A GPT model uses a causal mask AND a padding mask simultaneously.
4. Combining Masks
In practice, masks are combined additively. A decoder in an encoder-decoder model (like T5) uses:
- Causal mask on its own tokens (cannot look ahead)
- No mask on cross-attention to the encoder (can see the full encoded input)
- Padding mask on both (ignores padding in both sequences)
| Model | Self-attention | Cross-attention |
|---|---|---|
| BERT (encoder) | Bidirectional | — |
| GPT (decoder) | Causal | — |
| T5 encoder | Bidirectional | — |
| T5 decoder | Causal | Full (to encoder) |
Why −∞ Rather Than 0?
A natural question: why set masked positions to −∞ instead of 0?
After softmax, a score of 0 becomes e⁰/(e⁰ + others) > 0 — the token still gets some attention weight. Setting to −∞ gives e^(−∞) = 0 exactly, so masked positions contribute precisely zero to the weighted value sum. This is essential for causal masking — even a tiny weight on a future token would leak information.
float('-inf') rather than a very large negative number like −1e9, because on some hardware −1e9 divided by a large d_k can produce NaN gradients. True −∞ is numerically safe.Implementation Detail
In PyTorch, attention masks are typically boolean or float tensors added to raw scores before softmax:
# Causal mask for sequence length L
mask = torch.triu(torch.ones(L, L), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
attn_weights = torch.softmax(scores, dim=-1)
The masked_fill replaces masked positions with −∞. After softmax, those positions become exactly 0 — contributing nothing to the weighted value sum.
Summary
| Mask type | Allows | Used for |
|---|---|---|
| Bidirectional | All positions | Encoding, understanding |
| Causal | Past + present only | Language generation |
| Padding | Non-pad positions only | Batch processing |
| Combined | Intersection of rules | Encoder-decoder models |
Attention masks are the simplest mechanism in the Transformer, but they define the entire generative capability of the architecture. Change the mask, change the model family.
References
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. NeurIPS 2017 (introduces causal masking in the decoder to enforce autoregressive generation).
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019 (BERT: encoder-only model using bidirectional (non-causal) attention with padding masks for variable-length inputs).
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. OpenAI 2019 (GPT-2: decoder-only causal masking applied at scale for generative language modelling).
- [2] https://www.sscardapane.it/alice-book/