
NTK-Aware Scaling: Extending Context Without Fine-Tuning
Published:
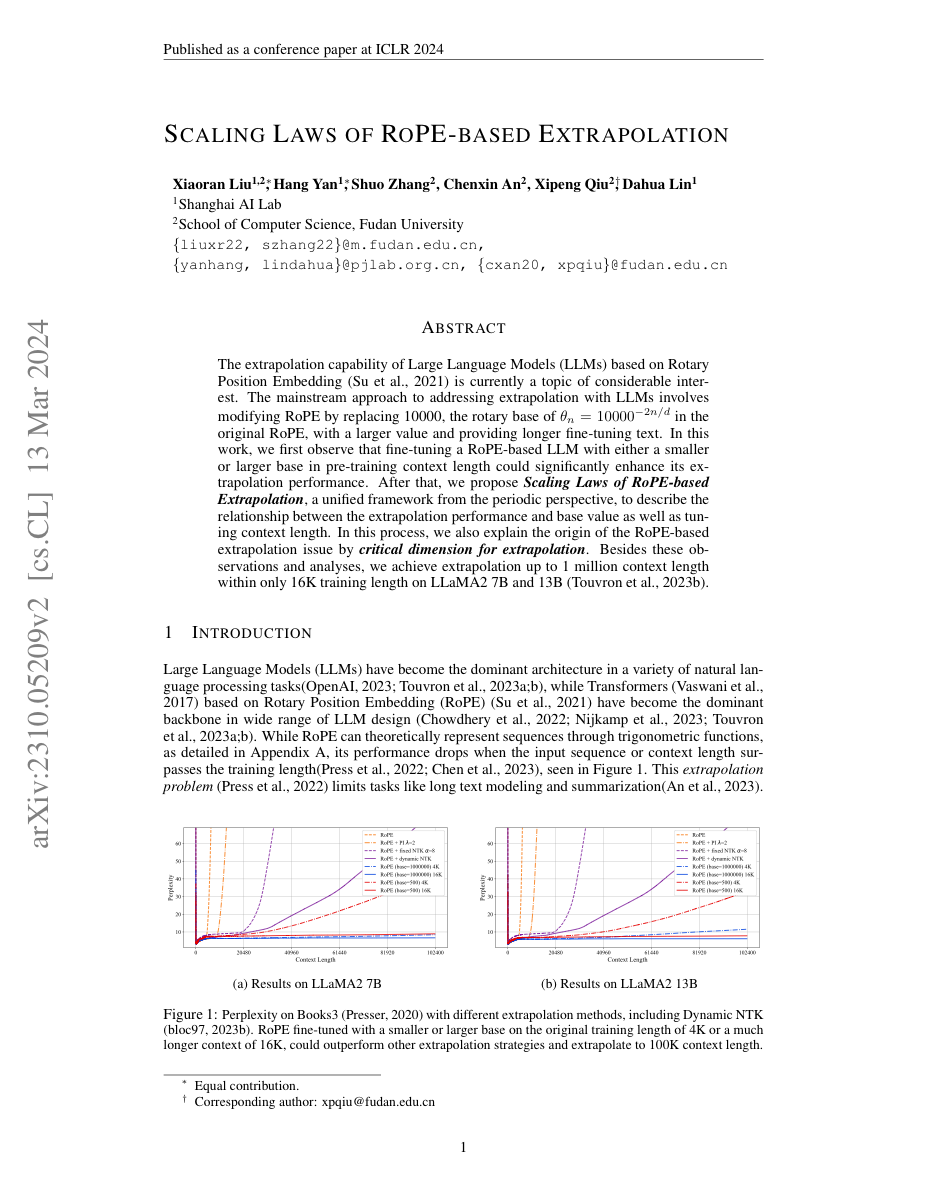
The Context Extension Problem
RoPE (Rotary Position Embedding) encodes the position of each token by rotating query and key vectors at dimension-specific frequencies. A model trained with RoPE on sequences up to length L learns to use those frequencies — but when you try to run it on sequences longer than L, the model sees rotation angles it has never encountered.
Naïve position interpolation (scaling positions linearly: pos → pos × L/L’) works but degrades high-frequency dimensions catastrophically — they change too fast across the rescaled positions, destroying local structure.
RoPE Frequencies: A Quick Recap
In RoPE, dimension pair i of a d_k-dimensional key or query is rotated by:
With base = 10000 (the original RoPE default), frequencies range from 1 (low-frequency, long-range position signal) to 1/10000^(d/d) ≈ 0.0001 (high-frequency, fine-grained local signal).
High-frequency dimensions complete many rotation cycles within a short context window. Low-frequency dimensions rotate slowly across the full context.
Visual Intuition: Frequency Saturation
What Breaks at Long Context
When context length exceeds training length, two problems arise:
High-frequency dimensions have seen all their cycles — they wrap around and lose uniqueness. Two distant positions may map to nearly the same rotation angle.
Attention patterns based on relative angles degrade — the model’s learned sense of “close” vs “far” tokens breaks down.
The NTK-Aware Scaling Insight
Proposed independently by /u/bloc97 on Reddit (2023) and connected to Neural Tangent Kernel theory, NTK-Aware Scaling replaces the base θ with a larger value:
Where:
- L = original training context length
- L’ = desired new context length
- d = head dimension
For example, extending LLaMA (trained at L=2048) to L’=8192:
This larger base stretches all frequencies proportionally. High-frequency dimensions that previously completed a full cycle within L tokens now complete their cycle within L’ tokens — no dimension becomes “saturated” at the new length.
NTK vs Linear Interpolation
| Method | High-freq dims | Low-freq dims | Fine-tuning needed |
|---|---|---|---|
| Linear interpolation | Severely degraded | Good | Often needed |
| NTK scaling | Preserved | Good | Usually not needed |
Linear interpolation scales positions but keeps frequencies fixed — the high-frequency dimensions see too many cycles per unit position. NTK scaling changes the frequencies to match the new scale.
Worked Example: Computing the NTK Base
Model: LLaMA-2 7B, trained at L = 4096, head dimension d = 128, original base = 10,000.
Target: extend to L’ = 32,768 (8× extension)
base_new = 10,000 × (32768 / 4096)^(128 / (128−2))
= 10,000 × 8^(128/126)
= 10,000 × 8^1.016
= 10,000 × 8.36
≈ 83,600
The new base of ~83,600 means every RoPE frequency θᵢ = 1/base^(2i/d) is reduced by a factor of ~8×, spreading cycles proportionally over 8× more tokens.
For dimension i = 0 (lowest frequency):
- Original: θ₀ = 1/10,000⁰ = 1.0 (full rotation per token — highest freq)
- After NTK: θ₀ = 1/83,600⁰ = 1.0 (unchanged — already handles short range fine)
For dimension i = 63 (highest frequency of the pair, near d/2):
- Original: θ₆₃ = 1/10,000^(126/128) ≈ 1/7,244 ≈ 0.000138
- After NTK: θ₆₃ = 1/83,600^(126/128) ≈ 1/60,600 ≈ 0.0000165
The highest-frequency dimension now completes its cycle every ~60,600 tokens instead of ~7,244 — scaled with the 8× target extension.
Dynamic NTK Scaling
A practical variant applies NTK scaling dynamically at inference time, adjusting the base only for sequences that exceed the training length:
def get_ntk_base(seq_len, training_len=2048, base=10000, dim=128):
if seq_len <= training_len:
return base
scale = seq_len / training_len
return base * (scale ** (dim / (dim - 2)))
This is zero-cost for short sequences and automatically extends context for long ones. LLaMA.cpp and many inference engines implement this by default.
Limitations
- NTK scaling degrades gradually as L’ / L increases. At 8× extension (e.g., 2k → 16k), quality noticeably drops without at least a small amount of fine-tuning.
- It is a post-hoc fix, not a principled training strategy. For best long-context performance, fine-tuning with the new scale (or using YaRN) is recommended.
- It does not address the attention sink problem — very long sequences still have attention pattern degradation.
Summary
| Property | Value |
|---|---|
| Core idea | Rescale RoPE base to stretch frequencies to longer contexts |
| Fine-tuning | Not required for moderate extension (2-4×) |
| Quality at 8× | Degrades; short fine-tune recommended |
| Implementation | Single hyperparameter change (new base value) |
| Relation to linear interpolation | Complementary — fixes what interpolation breaks |
NTK-Aware Scaling is the simplest way to extend the context of an existing RoPE model. For more sophisticated extension, see YaRN.
References
- Su, J., Lu, Y., Pan, S., Murtadha, A., Wen, B., & Liu, Y. (2021). RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv 2021 (RoPE: rotary position embeddings that encode relative positions; the basis for NTK-Aware Scaling).
- Bloc97 (2023). NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation. Reddit r/LocalLLaMA 2023 (original NTK-Aware Scaling proposal: rescales RoPE base to preserve high-frequency information during context extension).
- Chen, S., Wong, S., Chen, L., & Tian, Y. (2023). Extending Context Window of Large Language Models via Positional Interpolation. arXiv 2023 (Position Interpolation: the alternative to NTK scaling that linearly rescales positions — requires fine-tuning but more stable).