
Feed-Forward Networks: The Forgotten Half of Transformers
Published:
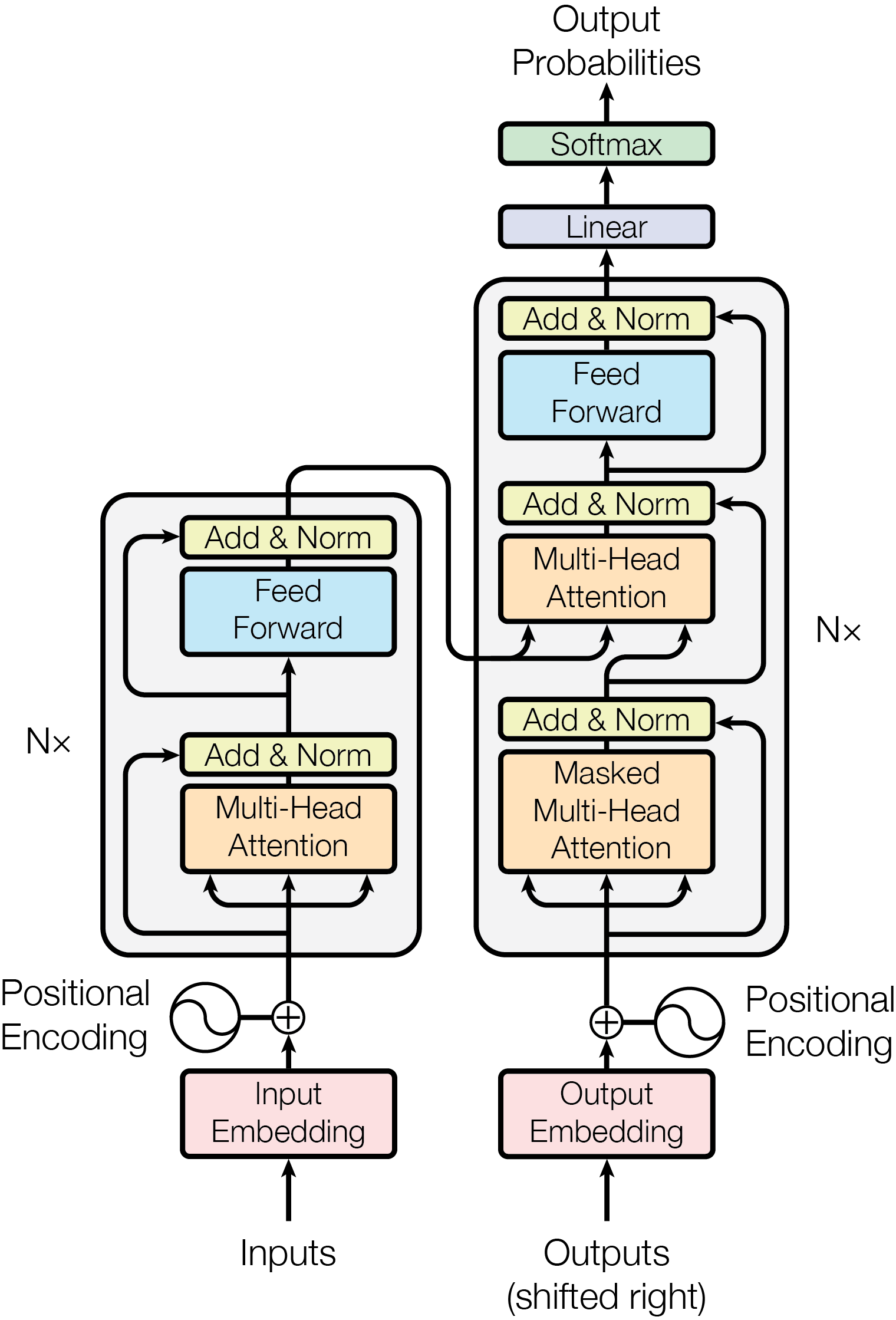
Intuition First: The FFN as a Pattern-Response Memory
Think of the FFN as a giant associative memory. The first matrix W₁ acts as a bank of pattern detectors — each row is a template asking “does this token look like X?” The nonlinearity fires neurons that match. The second matrix W₂ then says “when pattern X fires, add feature vector Y to the output.”
So for a token representing “Paris” in context “capital of France”, a neuron in the expanded layer might activate for the pattern “capital-of-Europe-city” and the corresponding W₂ column adds a “France-related” feature vector to the output. This is factual retrieval — not via attention, but via the FFN’s stored patterns.
The FFN Is Half the Block
Every Transformer block follows this pattern:
x → MultiHeadAttention → residual + LN → FeedForward → residual + LN → output
The FeedForward (FFN) sub-layer is the second half of every block. In popular Transformer explanations, it is often described in one sentence and then forgotten in favour of attention. This is a mistake — the FFN is critical.
The Architecture of the FFN
The FFN is a simple two-layer MLP applied position-wise: each token is processed identically and independently.
- W₁ ∈ ℝ^{d_model × d_ff}: projects up from d_model to d_ff
- activation: nonlinearity (ReLU, GELU, or SwiGLU)
- W₂ ∈ ℝ^{d_ff × d_model}: projects back down
- d_ff = 4 × d_model in most models (e.g., 512 → 2048, or 4096 → 16384)
The 4× expansion and contraction is standard but not derived from first principles — it was established empirically in the original paper and has remained the default.
Parameter Count: FFN Dominates
For a model with d_model = 1024 and d_ff = 4096, in each block:
| Sub-layer | Parameters |
|---|---|
| Multi-head attention (4 matrices) | 4 × 1024² = 4.2M |
| FFN (2 matrices) | 2 × 1024 × 4096 = 8.4M |
The FFN holds twice as many parameters as the attention sub-layer. In a 96-layer model, FFNs collectively account for roughly 2/3 of all parameters.
What Does the FFN Actually Do?
Attention vs FFN: Division of Labour
Research into Transformer internals has revealed a rough division:
- Attention heads move information between positions — they determine which tokens influence each other and gather context
- FFN layers process information at a single position — they apply transformations and recall facts
This is why you can have a model that “knows” Paris is the capital of France even though that fact was not encoded in the positional attention pattern of the current context — the FFN retrieves it.
FFN as a Key-Value Memory
A 2020 paper (Geva et al., “Transformer Feed-Forward Layers Are Key-Value Memories”) showed that the FFN can be interpreted as:
- W₁ rows (the “keys”): pattern detectors — each neuron in the expanded dimension activates for specific input patterns
- W₂ columns (the “values”): for each activated key, the corresponding value vector is added to the output
When a token activates a key neuron (because it matches a learned pattern), the associated value is retrieved and added to the representation. This is analogous to a soft content-addressable memory — the FFN stores and retrieves (token, fact) associations.
The Nonlinearity: ReLU, GELU, SwiGLU
ReLU (original Transformer, 2017)
Simple and sparse — negative activations are exactly zero, which gives the FFN a sparse, efficient structure.
GELU (GPT-2, BERT, and successors)
Smooth approximation of ReLU with non-zero gradient for negative inputs. Empirically outperforms ReLU on most language tasks.
SwiGLU (LLaMA, PaLM, Mistral)
A gated variant: two parallel linear projections, one gating the other element-wise. SwiGLU-based FFNs use d_ff = (8/3) × d_model (not 4×) to keep parameter count comparable. Consistently outperforms ReLU and GELU at large scale.
Position-Wise Independence: A Key Property
The FFN processes each token independently — it does not look at neighbouring tokens. There is no attention-like mechanism: the computation for position i uses only the vector at position i.
This means:
- Parallelisable across positions (all tokens in a sequence processed simultaneously)
- No position-to-position information mixing — that is strictly the role of attention
- The FFN refines each token’s representation in place; it does not redistribute information
Worked Example: Parameter Count in GPT-3
GPT-3: d_model = 12,288 · d_ff = 49,152 (4×) · 96 layers
Per layer FFN parameters:
- W₁: 12,288 × 49,152 = 603.9M
- W₂: 49,152 × 12,288 = 603.9M
- Total FFN per layer: ≈1.21B
Per layer MHA parameters (96 heads, d_k = d_v = 128):
- Q, K, V, O projections: 4 × 12,288² = 603.9M
Across 96 layers:
- All FFNs: 96 × 1.21B ≈ 116B parameters
- All MHA: 96 × 603.9M ≈ 58B parameters
- FFN share: ≈ 67% of the 175B total
This confirms the rule: in any standard Transformer, the FFN holds roughly two-thirds of all parameters. Scaling the model mostly means scaling the FFN.
Sparse FFNs: MoE
Mixture-of-Experts (MoE) Transformers replace the dense FFN with multiple expert FFNs, routing each token to only a subset (often 2 out of 64 or more experts):
token → router → expert_k → output
This allows vastly more total parameters (stored in expert FFNs) while keeping computation constant (only a fraction is used per token). Models like Mixtral 8×7B and GPT-4 (allegedly) use MoE in the FFN sub-layer.
Summary
| Property | Value |
|---|---|
| Architecture | Two-layer MLP with expansion |
| Expansion factor | 4× (ReLU/GELU) or 8/3× (SwiGLU) |
| Applied to | Each token independently |
| Parameter share | ~2/3 of total in standard models |
| Information role | Per-position processing and fact retrieval |
| Attention role comparison | Attention mixes positions; FFN refines each position |
The FFN is not attention’s sidekick. It is an equal partner — the knowledge storage and processing unit that sits beside attention’s information-routing mechanism.
References
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. NeurIPS 2017 (Transformer FFN: two-layer MLP with ReLU, dimension 4d hidden, applied position-wise after each attention sublayer).
- Geva, M., Schuster, R., Berant, J., & Levy, O. (2021). Transformer Feed-Forward Layers Are Key-Value Memories. EMNLP 2021 (shows that FFN keys activate for human-interpretable input patterns and values store associated output information — FFN as learned key-value memory).
- Shazeer, N. (2020). GLU Variants Improve Transformer. arXiv 2020 (SwiGLU: gated linear units replacing ReLU in the FFN — now the dominant activation in LLaMA, Mistral, PaLM, and Gemini).