
Encoder vs Decoder vs Encoder-Decoder Transformers
Published:
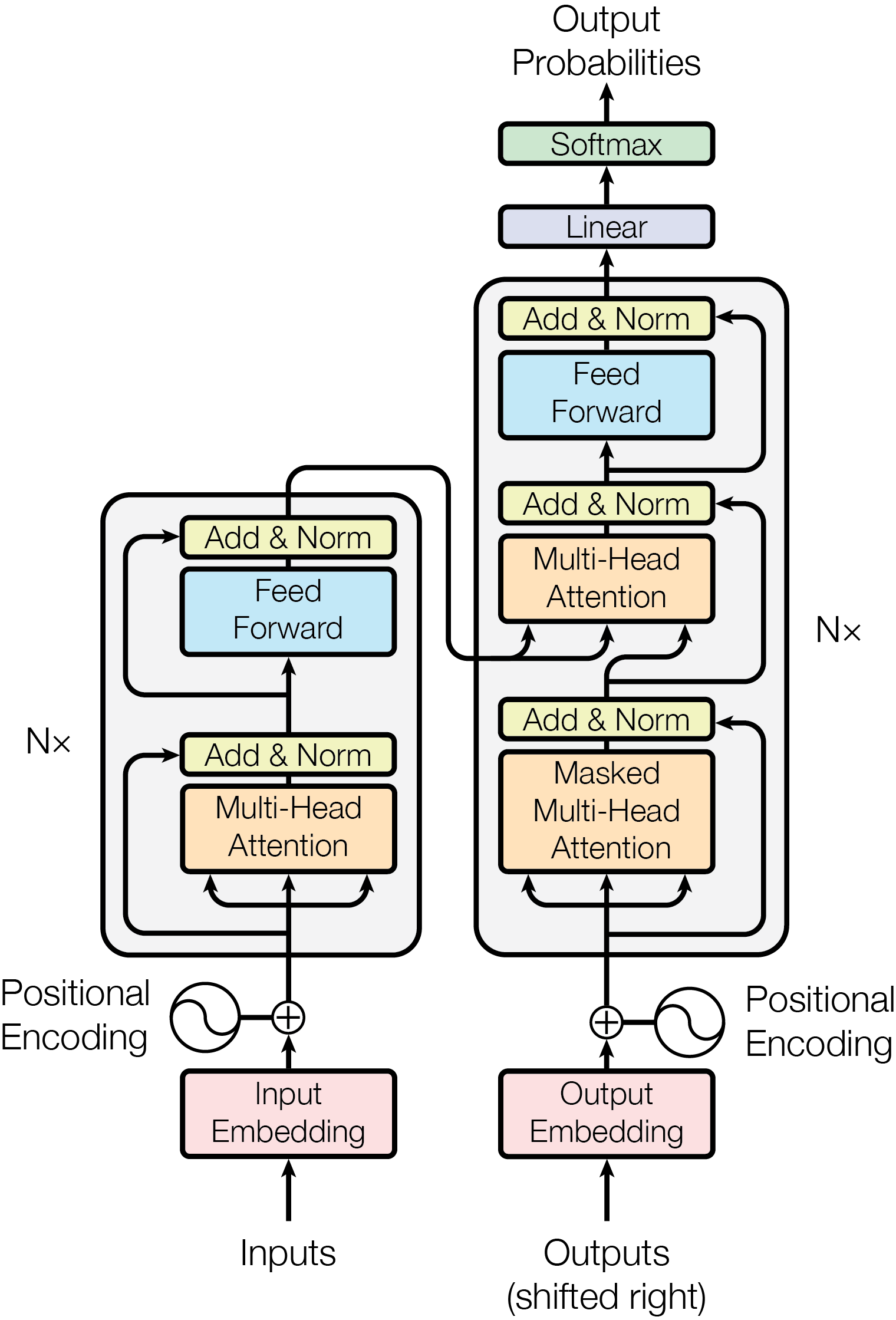
The Three Families
The original 2017 Transformer (“Attention Is All You Need”) was an encoder-decoder. The field then diverged into three distinct families, each optimised for different tasks.
1. Encoder-Only: BERT-style
Each encoder block contains:
- Bidirectional self-attention (every token sees every other token)
- Feed-forward network
- Layer norm + residual connections
Training objective: Masked Language Modelling (MLM). Random tokens in the input are replaced with [MASK], and the model predicts them. Because the answer is already in the sequence (just hidden), the model can attend bidirectionally.
What this is good at:
- Sentence classification (spam detection, sentiment)
- Token classification (NER, POS tagging)
- Question answering (span extraction)
- Sentence embeddings (semantic search)
What this cannot do: autoregressive generation. Generating token N+1 requires seeing token N+1 (bidirectional), which is circular during inference.
Examples: BERT, RoBERTa, DeBERTa, ALBERT, ModernBERT.
2. Decoder-Only: GPT-style
Each decoder block contains:
- Causal (masked) self-attention (each token sees only past tokens)
- Feed-forward network
- Layer norm + residual connections
Note: there is no cross-attention in decoder-only models. Each decoder block has only two sub-layers (not three), because there is no encoder output to attend to.
Training objective: Next-token prediction. Given tokens 1…N, predict token N+1. The causal mask ensures no peeking.
What this is good at:
- Text generation (stories, code, completions)
- In-context learning (few-shot prompting)
- Instruction following (with RLHF/fine-tuning)
- Anything you can frame as completion
What this is less natural for: tasks that require reading the full input before producing an output (e.g., translation, summarisation) — though modern large decoder-only models handle these with prompting anyway.
Examples: GPT-2, GPT-3, GPT-4, LLaMA, Mistral, Gemma, Claude.
3. Encoder-Decoder: T5-style
The encoder processes the full input bidirectionally. The decoder generates the output token by token, using:
- Causal self-attention (on its own generated tokens so far)
- Cross-attention (queries the encoder’s output at each step)
- Feed-forward network
Training objective: Span corruption (T5) or similar sequence-to-sequence objectives.
What this is good at:
- Machine translation (full input available, output generated)
- Summarisation (read document, write summary)
- Question answering with generation (read context, write answer)
- Any task naturally framed as input → output transformation
Examples: T5, BART, mT5, Flan-T5, NLLB (translation).
Side-by-Side Comparison
| Property | Encoder-only | Decoder-only | Encoder-Decoder |
|---|---|---|---|
| Self-attention type | Bidirectional | Causal | Both |
| Cross-attention | None | None | Decoder → Encoder |
| Reads input | Fully, in parallel | Autoregressively | Fully (encoder) |
| Generates output | No (fixed-length) | Autoregressively | Autoregressively |
| Training objective | MLM, NSP | Next-token prediction | Seq2seq |
| Good for | Understanding | Generation | Transformation |
| Examples | BERT, DeBERTa | GPT, LLaMA, Claude | T5, BART, Flan-T5 |
The Attention Mask Differences
Encoder self-attention (bidirectional):
✓ ✓ ✓ ✓
✓ ✓ ✓ ✓
✓ ✓ ✓ ✓
✓ ✓ ✓ ✓
Decoder self-attention (causal):
✓ ✗ ✗ ✗
✓ ✓ ✗ ✗
✓ ✓ ✓ ✗
✓ ✓ ✓ ✓
Decoder cross-attention (full encoder access):
✓ ✓ ✓ ✓ ← decoder pos 1 attends to all encoder positions
✓ ✓ ✓ ✓ ← decoder pos 2 attends to all encoder positions
The mask tells the whole story. Encoder: open. Decoder: lower triangular. Cross-attention: open to the encoder.
Concrete Worked Example: Translating “The cat sat”
To make the three architectures concrete, consider translating “The cat sat” into French (“Le chat s’est assis”).
Encoder (reads input):
Tokens [The, cat, sat] enter simultaneously. At layer 1, cat attends to both The and sat — bidirectional context tells it this is a subject noun, not a verb. All positions are processed in parallel.
Decoder step 1 (generates “Le”):
Input to decoder: [<BOS>]. Causal self-attention: only position 0 is visible. Cross-attention: <BOS> queries the encoder’s full representation of [The, cat, sat] and retrieves a weighted mixture centred on “The”. Output distribution peaks at “Le”.
Decoder step 2 (generates “chat”):
Input: [<BOS>, Le]. Causal self-attention: position 1 can see position 0 (“Le”) but not future tokens. Cross-attention: “Le” queries the encoder and attends heavily to “cat”. Output: “chat”.
Decoder step 3 (generates “s’est”):
Input: [<BOS>, Le, chat]. Cross-attention now attends to the verb “sat”. Autoregressive chain continues until <EOS>.
This step-by-step shows why encoder-decoder wins for translation: the encoder reads all context before any generation begins, and cross-attention lets each decoder step query that full context freely.
Summary
The three architectures are not better or worse in absolute terms — they are optimised for different settings:
- Understanding a fixed input? → Encoder-only
- Generating open-ended text? → Decoder-only
- Transforming one sequence into another? → Encoder-decoder
Modern LLMs (GPT-4, Claude, LLaMA) are decoder-only, using scale and prompting to cover all three use cases. But for specialised tasks with a clear input-output structure and limited compute, encoder-decoder models remain competitive.
References
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. NeurIPS 2017 (original encoder-decoder Transformer for machine translation).
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019 (BERT: the canonical encoder-only Transformer for classification and understanding tasks).
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., & Liu, P. J. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. JMLR 2020 (T5: unifies NLP tasks under a single encoder-decoder text-to-text format).
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., et al. (2020). Language Models are Few-Shot Learners. NeurIPS 2020 (GPT-3: decoder-only architecture at 175B parameters demonstrating few-shot learning).