
Cross-Attention: How Models Attend to Another Sequence
Published:
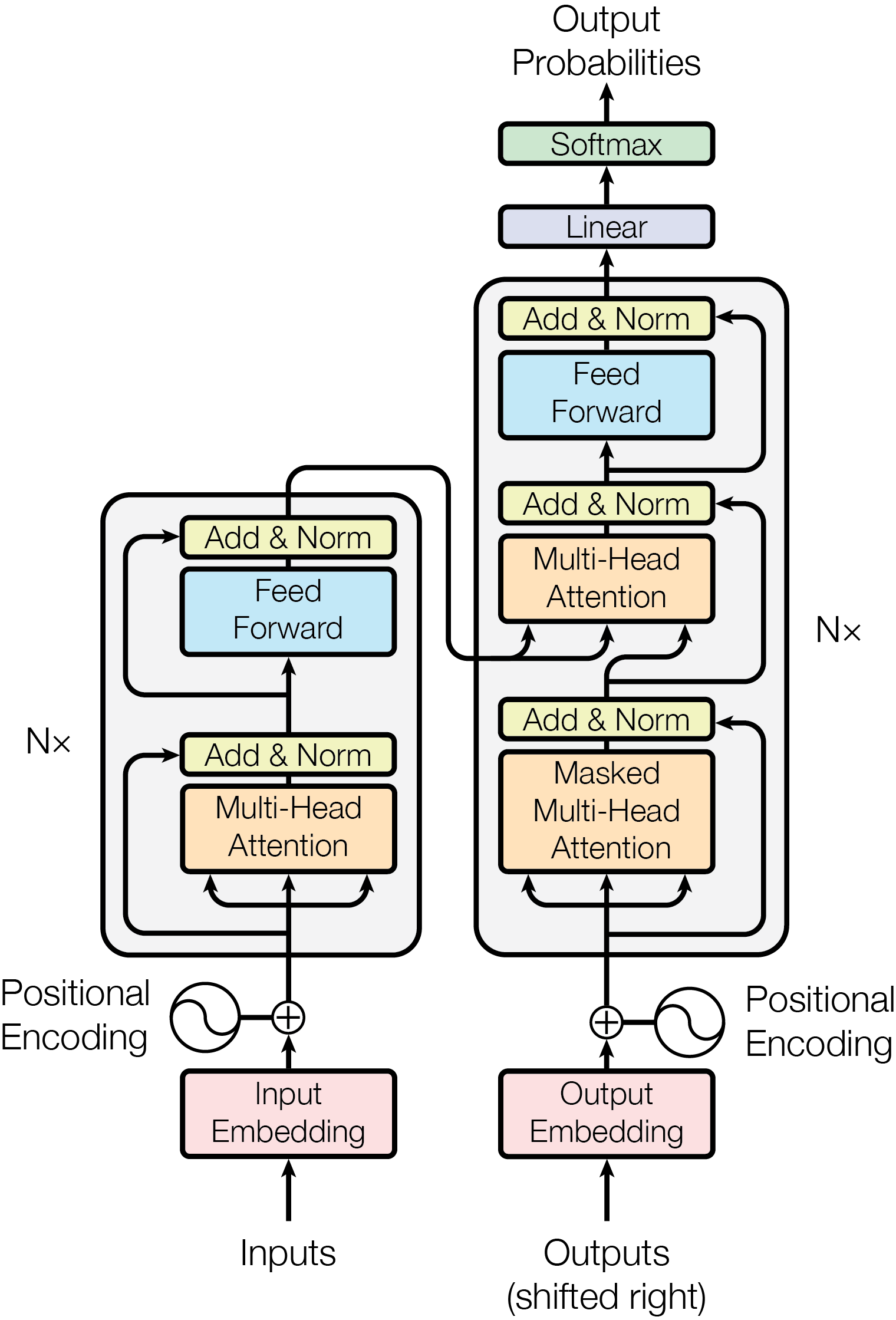
Self-Attention vs Cross-Attention
In self-attention, every token looks at every other token within the same sequence:
Q = X · W_Q (from the same sequence X)
K = X · W_K (from the same sequence X)
V = X · W_V (from the same sequence X)
In cross-attention, queries come from one sequence, but keys and values come from another:
Q = X_dec · W_Q (from the decoder sequence)
K = X_enc · W_K (from the encoder output)
V = X_enc · W_V (from the encoder output)
The output has the same length as the query sequence (decoder), but each position has gathered information from the full key-value sequence (encoder).
The Translation Analogy
Think of translating English → French.
The encoder reads the full English sentence and computes rich contextual representations: every English word has seen every other English word.
The decoder generates French words one at a time. At each step, it needs to ask: which English words are most relevant to the French word I am about to produce?
That is cross-attention:
- Q = the current French position being generated (decoder)
- K, V = all English token representations (encoder)
- Output = a blend of English information, weighted by relevance to the current French word
Where Cross-Attention Appears
1. Encoder-Decoder Transformers (T5, BART, original Transformer)
Each decoder layer has three sub-layers:
- Masked self-attention (decoder attends to its own past tokens)
- Cross-attention (decoder attends to encoder output)
- Feed-forward network
The cross-attention layer is what connects the two towers. Remove it, and the decoder has no way to condition on the input.
2. Image Captioning
- Encoder: a vision model (CNN or ViT) processes the image → spatial feature map
- Decoder: a language model generates the caption
- Cross-attention: each generated word queries which image regions are most relevant
3. Diffusion Models (Stable Diffusion, DALL-E 2)
- Encoder: CLIP or T5 encodes the text prompt → contextual embeddings
- Decoder: the UNet denoising network
- Cross-attention: each spatial location in the noisy image queries the text tokens to determine what to generate there
This is why changing a single word in a prompt changes the relevant regions of the generated image — cross-attention routes each spatial location to the relevant text signal.
4. Multimodal Models (Flamingo, BLIP-2)
Cross-attention allows visual tokens to query language tokens and vice versa — the fundamental mechanism for grounding language in images.
Worked Example: 3-Token Translation
Translating “The cat sat” (3 English tokens) → “Le chat s’est assis” (4 French tokens).
Encoder processes [The, cat, sat] → produces key-value pairs K_enc, V_enc (shape 3×d_model).
Decoder generates each French token one at a time. When generating “chat” (token 2):
Q_dec = W_Q · h_decoder["chat position"] → shape 1×d_k
K_enc = W_K · [The, cat, sat] → shape 3×d_k
V_enc = W_V · [The, cat, sat] → shape 3×d_v
scores = Q_dec · K_enc^T = [s_The, s_cat, s_sat]
≈ [0.10, 0.85, 0.05] (after softmax)
output = 0.10·v_The + 0.85·v_cat + 0.05·v_sat
“chat” attends mostly to “cat” — the cross-attention map recovers the word alignment without any explicit supervision.
The Attention Map Has a New Shape
In self-attention on a sequence of length N, the attention matrix is N×N.
In cross-attention, if the query sequence has length M (decoder) and the key-value sequence has length N (encoder), the attention matrix is M×N.
Each of the M output positions independently attends over all N input positions. The output tensor is M×d_v — same length as the query sequence, same value dimension.
Cross-Attention Visualised
For the translation pair “The cat sat” → “Le chat s’est assis”:
The cat sat
Le 0.8 0.1 0.1 → "Le" attends mostly to "The"
chat 0.1 0.85 0.05 → "chat" attends mostly to "cat"
s'est 0.1 0.05 0.85 → "s'est" attends mostly to "sat"
assis 0.05 0.1 0.85 → "assis" attends mostly to "sat"
The attention pattern learned by a well-trained translation model tends to align source and target words — a property that emerged from training, not from any explicit alignment supervision.
Summary
| Property | Self-Attention | Cross-Attention |
|---|---|---|
| Q source | Same sequence | Different sequence (decoder) |
| K, V source | Same sequence | Different sequence (encoder) |
| Output length | Same as input | Same as Q sequence |
| Attention shape | N × N | M × N |
| Role | Contextualise within sequence | Bridge two sequences |
Cross-attention is the fundamental building block for any model that needs to condition generation on a separate encoded representation — translation, captioning, diffusion, and multimodal understanding all rely on it.
References
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. NeurIPS 2017 (introduces cross-attention in the decoder: queries from the target sequence attend over encoder keys and values).
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., & Liu, P. J. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. JMLR 2020 (T5: encoder-decoder model built entirely around cross-attention for text-to-text transfer learning).
- Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022 (Stable Diffusion: cross-attention between text and image latents for text-conditioned image generation).