
Robot Sensors: Cameras, LiDAR, and IMUs
Published:
Sensor Modalities
RGB cameras are the most widely deployed sensor in robotics. They capture rich texture and color information at low cost. However, they are projective sensors — depth information is lost in the 2D image plane. Stereo cameras recover depth via triangulation but require careful calibration and struggle with textureless regions.
RGB-D cameras (e.g., Intel RealSense, Microsoft Kinect) add per-pixel depth using structured light or time-of-flight. They provide a registered color-depth image pair, enabling direct 3D reconstruction at short range (0.2–4 m). At longer ranges or in outdoor bright light, structured light degrades.
LiDAR (Light Detection and Ranging) emits laser pulses and measures time-of-flight to reconstruct precise 3D point clouds. A Velodyne HDL-64E generates 1.3 million points per second with centimetre-level accuracy and 360° horizontal field of view. LiDAR is robust to lighting conditions and long-range, but expensive and sparse — objects have far fewer LiDAR points than image pixels.
Inertial Measurement Units (IMUs) combine accelerometers and gyroscopes to measure linear acceleration and angular velocity at 100–1000 Hz. IMUs are lightweight, cheap, and fast — but suffer from integration drift. A small bias in the accelerometer grows to significant position error after a few seconds of dead-reckoning.
Force/torque sensors at the wrist measure contact forces in 6-DOF (3 forces, 3 torques). They are essential for compliant manipulation, assembly tasks, and safe human-robot interaction.
Calibration: Intrinsic and Extrinsic
Intrinsic calibration determines the camera’s internal parameters. The pinhole camera model projects a 3D point \(\mathbf{P}_w\) to image coordinates \(\mathbf{p}\) via the camera matrix \(K\):
where \(f_x, f_y\) are focal lengths in pixels, \((c_x, c_y)\) is the principal point, and the extrinsic matrix \([R \mid t]\) maps world to camera coordinates. Lens distortion adds radial and tangential correction terms. Calibration uses checkerboard patterns (Zhang 2000) to solve for \(K\) and distortion coefficients.
Extrinsic calibration determines the rigid-body transform between sensor coordinate frames — e.g., the LiDAR-to-camera transform \(T_{LC} \in SE(3)\). This is done by finding correspondences between 3D LiDAR points and 2D image points on a calibration target.
Sensor Fusion: Kalman Filtering
The Extended Kalman Filter (EKF) is the standard tool for fusing IMU measurements with slower, noisier sensors (GPS, wheel odometry, vision). The filter maintains a Gaussian belief over robot state \(\mathbf{x}\) (position, velocity, orientation):
Update: $$K_k = P_{k|k-1} H^T (H P_{k|k-1} H^T + R)^{-1}$$
$$\mathbf{x}_k = \hat{\mathbf{x}}_{k|k-1} + K_k(z_k - h(\hat{\mathbf{x}}_{k|k-1}))$$
The IMU provides high-rate predictions (predict step); GPS or visual odometry provides corrections (update step). The complementary filter structure makes the combination robust: IMU covers high-frequency motion, external sensors correct low-frequency drift.
Point Cloud Processing
Raw LiDAR or RGBD data arrives as an unordered point cloud \(\mathcal{P} = \{p_i\}_{i=1}^N\) where each \(p_i \in \mathbb{R}^3\) (or \(\mathbb{R}^6\) with normals). Standard 3D convolutions do not apply to irregular point clouds.
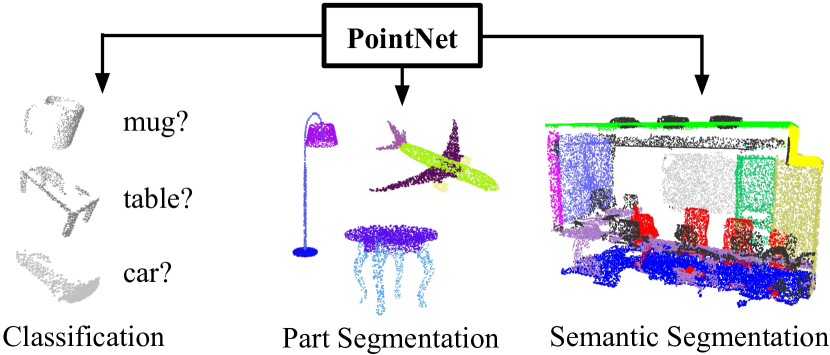
PointNet (Qi et al. 2017) solves this with a permutation-invariant architecture: apply a shared MLP to each point independently, then aggregate with a global max-pool. Despite its simplicity, PointNet achieves strong results on 3D object classification and segmentation. PointNet++ extends this with hierarchical local feature aggregation using ball queries, capturing local geometry at multiple scales.
VoxelNet discretises the point cloud into a regular voxel grid and applies 3D convolutions — more computationally expensive but captures local density structure. Modern LiDAR detectors (CenterPoint, VoxelNeXt) combine voxelisation with sparse convolutions for efficient inference.
References
- Thrun, S., Burgard, W., & Fox, D. (2005). Probabilistic Robotics. MIT Press.
- Qi, C. R., Su, H., Mo, K., & Guibas, L. J. (2017). PointNet: Deep learning on point sets for 3D classification and segmentation. CVPR. arXiv:1612.00593.
- Zhang, Z. (2000). A flexible new technique for camera calibration. IEEE TPAMI, 22(11), 1330–1334.