
Open Problems in Robot Learning
Published:
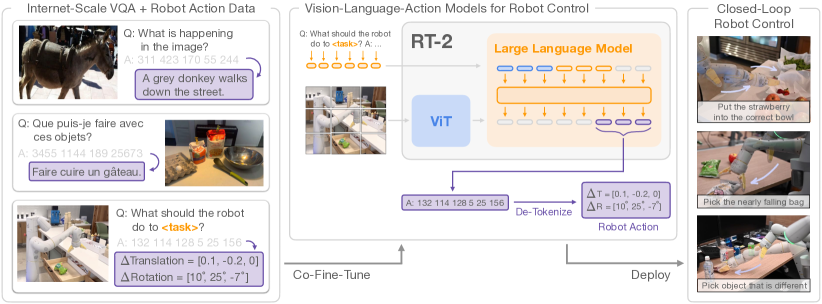
The Data Bottleneck
Language models trained on the internet saw roughly a trillion tokens of text. The largest robot dataset (Open X-Embodiment) contains about a million demonstrations — six orders of magnitude smaller. This data gap is not just a matter of compute: robot data is expensive to collect because it requires physical hardware, teleoperation, and human time.
The consequences are severe: robot policies generalise poorly to novel objects, lighting conditions, and spatial configurations. A model that sees 100 demonstrations of picking mugs will fail on the 101st if it has an unusual shape.
Proposed solutions include:
- Internet-scale video pre-training: pre-train visual representations on YouTube/web video of humans manipulating objects (R3M, MVP, DreamerV3).
- Automated data collection: robots that autonomously explore and self-label successes (AutoRT, Google 2023).
- Cross-embodiment transfer: train on data from many different robot types and fine-tune to the target embodiment (Open X-Embodiment approach).
- Simulation scale-up: generate unlimited synthetic demonstrations in simulation with automatic domain randomisation.
None of these fully resolves the data problem — each comes with its own limitations and failure modes.
Generalisation vs. Specialisation
There is a fundamental tension in robot learning between generalisation (a single policy that handles diverse tasks and environments) and specialisation (a dedicated policy that handles one task extremely well). Foundation model robots (RT-2, Octo) optimise for generalisation but typically underperform task-specific models on any individual task. Industrial robots are supremely specialised but cannot handle novel scenarios.
Human dexterity achieves both: a chef can perform hundreds of fine-grained manipulation tasks with a single set of hands and a shared neural substrate. Understanding how to reconcile generalisation and specialisation — through efficient multi-task learning, meta-learning, or architectural priors — remains an open research question.
Tactile Sensing
Humans manipulate objects with rich tactile feedback: texture, temperature, compliance, slip detection. Most robot manipulation research relies entirely on vision and proprioception, ignoring touch. This limits manipulation to relatively rigid, visually distinctive objects in well-lit environments.
Tactile sensors — from resistive arrays to GelSight optical tactile sensors — can provide rich contact information but introduce new challenges:
- High dimensionality: a GelSight sensor provides a full image of the contact surface.
- Sim-to-real gap: tactile signals are notoriously hard to simulate accurately.
- Fusion with vision: how to effectively combine visual and tactile information in policy architectures remains unclear.
Recent work on tactile robot learning (Lambeta et al. 2020 DIGIT sensor; Higuera et al. 2023 tactile policies) is beginning to close this gap, but tactile sensing remains far from mainstream adoption in robot learning.
Long-Horizon Reasoning
Current robot learning systems excel at short-horizon tasks (5–30 seconds). Cleaning a kitchen, building flat-pack furniture, or preparing a meal involves hundreds of steps over minutes to hours. The challenges compound:
- Sparse rewards: feedback may come only at task completion.
- Error accumulation: small mistakes in early steps can render later steps impossible.
- Memory: the robot must remember what it has done to plan what to do next.
- Recovery: when a step fails, the robot must diagnose the failure and adapt its plan.
Hierarchical learning, model-based planning, and neuro-symbolic integration are active research directions, but no approach yet robustly handles long-horizon manipulation in unstructured environments.
Embodied AI and Internet-Scale Pre-training
Embodied AI is the broader research programme of building agents that learn through physical interaction with the world — not just from text or images. The central open question: how much can internet-scale pre-training substitute for embodied experience?
Large language and vision models clearly provide useful semantic knowledge for robots (demonstrated by SayCan, RT-2, etc.). But they lack physical intuition — intuitive physics, haptic knowledge, the feel of how objects behave under manipulation. This physical knowledge may only be learnable through embodied experience, not observation.
Bommasani et al. (2021) highlighted this as a fundamental open question for foundation models: can models that have never touched the world develop robust understanding of it?
Other Frontier Problems
- Multi-robot coordination: how do teams of robots share experience and coordinate without explicit communication overhead?
- Continual learning: how does a robot accumulate skills over its lifetime without forgetting previously learned capabilities (catastrophic forgetting)?
- Causal understanding: can robots learn causal models of their environment to support counterfactual reasoning (“if I push here, what happens to the stack”)?
- Human-robot collaboration: how do robots predict human intentions, communicate their own plans, and adapt their behaviour in real time during shared tasks?
The Path Forward
Robot learning has transformed from carefully hand-engineered motion controllers to end-to-end learned policies that can follow language instructions and transfer across embodiments. The remaining challenges are deep but tractable. Progress will likely come from: larger and more diverse datasets, better integration of physical structure and learned representations, multi-modal sensing, and hybrid architectures that combine the reliability of classical robotics with the flexibility of learned policies.
The robot that can reliably help with daily life — in homes, hospitals, and disaster zones — remains the field’s north star.
References
- Doshi-Velez, F., & Kim, B. (2017). Towards a rigorous science of interpretable machine learning. arXiv:1702.08608.
- Bommasani, R., et al. (2021). On the opportunities and risks of foundation models. arXiv:2108.07258.
- Padalkar, A., et al. (2023). Open X-Embodiment: Robotic learning datasets and RT-X models. arXiv:2310.08864.
- Lambeta, M., et al. (2020). DIGIT: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation. IEEE RA-L, 5(3), 3838–3845.
- Ha, D., & Schmidhuber, J. (2018). World models. NeurIPS 2018. arXiv:1803.10122.
- Zeng, A., et al. (2022). Robotic view planning for in-hand manipulation. Science Robotics.
- Brohan, A., et al. (2023). AutoRT: Embodied foundation models for large scale orchestration of robotic agents. arXiv:2401.12963.