
Robot Locomotion: Walking, Running, and Jumping
Published:
The Locomotion Challenge
Legged locomotion is fundamentally a problem of controlling dynamic, underactuated systems in continuous contact with an uncertain environment. Classical approaches relied on carefully engineered gaits, zero-moment point (ZMP) control, and model predictive control with manually designed contact schedules. These methods work reliably on flat terrain but struggle with stairs, rubble, and dynamic disturbances.
Deep reinforcement learning has changed this picture dramatically. RL-trained policies learn to coordinate many joints simultaneously, adapt contact schedules implicitly, and develop robust recovery behaviours — capabilities that took years to engineer classically.
MuJoCo and the RL Locomotion Benchmark
MuJoCo (Multi-Joint dynamics with Contact, Todorov et al. 2012) became the standard simulator for learning locomotion policies. Its accurate contact dynamics and fast simulation made it ideal for the compute-intensive rollouts that RL requires. Classic MuJoCo benchmarks — HalfCheetah, Ant, Hopper, Humanoid — established standard evaluation protocols and drove rapid algorithmic progress.
The reward structure in MuJoCo locomotion typically balances:
penalising energy expenditure (joint torques \(\tau\)) and impact forces while rewarding forward velocity. This reward shaping encourages efficient, natural-looking gaits to emerge.
ANYmal: RL for Quadruped Locomotion
ANYmal (Lee et al. 2020) is a quadruped robot developed at ETH Zurich that achieved a landmark result: a single RL policy controlling all 12 joints, trained entirely in simulation, that could traverse challenging terrain (stairs, slopes, debris) and recover from pushes in the real world.
Key design elements:
- Privileged training: the critic receives ground truth terrain height maps and contact forces; the actor receives only proprioceptive observations (joint angles, velocities, IMU). This asymmetry allows the critic to guide the actor toward robust, estimable behaviours.
- Terrain curriculum: training starts on flat terrain and progressively introduces more challenging obstacles as the policy improves.
- Domain randomisation: mass, friction, and actuator parameters are randomised to enable sim-to-real transfer.
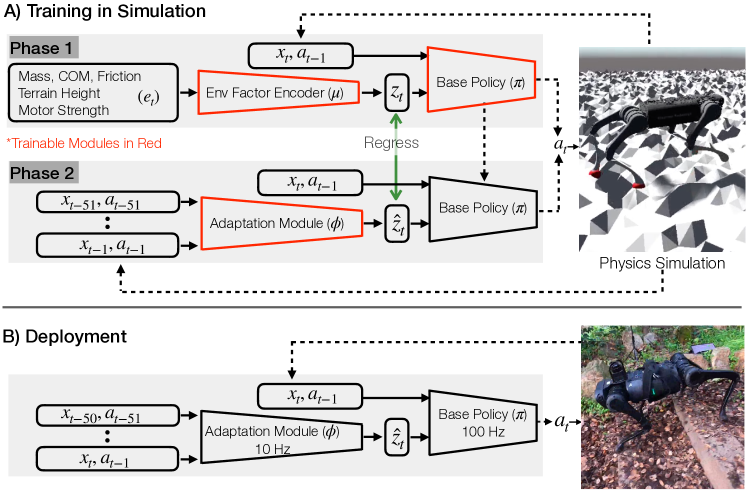
Rapid Motor Adaptation (RMA)
RMA (Kumar et al. 2021, arXiv:2107.04034) extends the privileged-training paradigm with explicit online adaptation. RMA trains a base policy conditioned on an environment embedding \(z\) (encoding physical parameters like mass and friction), then distils an adaptation module that estimates \(z\) from a short history of proprioceptive observations. At deployment, the adaptation module continuously updates \(z\) in real time, enabling the policy to rapidly adapt to new terrain and physical conditions within seconds of first contact.
Cassie and Bipedal Locomotion
Bipedal locomotion is harder than quadrupedal — the robot must maintain balance on two legs with a high centre of mass. Cassie (Agility Robotics) demonstrated RL-trained walking, running, and stair climbing. A key challenge is the point-foot contact model (Cassie has no flat feet), which requires precise timing of contact events.
Training involves additional constraints to prevent falls during learning, often implemented via early termination (resetting episodes when the robot tips past a threshold angle) and reference-motion tracking (initialising the policy close to a reference trajectory to guide exploration).
Parkour and Extreme Agility
Recent work by Zhuang et al. (2023) and others demonstrated parkour-capable quadrupeds that can jump, climb, and vault obstacles. These policies are trained with increasingly difficult terrain curricula and leverage the full dynamic range of the robot’s actuators. The gap between simulation and reality is bridged with careful domain randomisation and real-world fine-tuning.
References
- Kumar, A., et al. (2021). RMA: Rapid motor adaptation for legged robots. RSS 2021. arXiv:2107.04034.
- Lee, J., et al. (2020). Learning quadrupedal locomotion over challenging terrain. Science Robotics, 5(47).
- Hwangbo, J., et al. (2019). Learning agile and dynamic motor skills for legged robots. Science Robotics, 4(26).
- Miki, T., et al. (2022). Learning robust perceptive locomotion for quadrupedal robots in the wild. Science Robotics, 7(62).
- Todorov, E., Erez, T., & Tassa, Y. (2012). MuJoCo: A physics engine for model-based control. IROS 2012.
- Zhuang, Z., et al. (2023). Robot parkour learning. CoRL 2023.