
Foundation Models for Robotics: RT-1, RT-2, and Beyond
Published:
The Case for Scale in Robot Learning
Individually trained robot policies are brittle: a model trained to pick apples often fails on oranges. The success of large language models taught us that scale — more data, more parameters, more compute — enables emergent generalisation. The central question for robotics is: does the same principle apply when the “language” is actions?
The answer emerging from RT-1, RT-2, and their successors is: yes, but it requires large, diverse robot datasets and architectures that can absorb and transfer that diversity.
RT-1: Transformer for Robot Learning
RT-1 (Brohan et al. 2022, arXiv:2212.06817) trained an 35M-parameter EfficientNet + Transformer architecture on a dataset of 130,000 demonstrations collected over 17 months by 13 robots in Google’s office kitchens. Tasks spanned picking, placing, opening drawers, and knocking over objects — 700+ distinct tasks with natural language instructions.
The architecture:
- An EfficientNet-B3 image encoder processes each camera frame.
- A TokenLearner module compresses visual tokens from 81 to 8.
- A Transformer decoder attends over language tokens and 6 image frames to predict robot actions.
- Output: a tokenised 7-DOF robot action (discrete bins for each joint + gripper).
where \(o_{t-5:t}\) is a stack of recent observations and \(l\) is the language instruction.
RT-1 achieved 97% success on seen tasks and, crucially, ~25% success on novel tasks not in the training set — demonstrating that broad training improves generalisation beyond specialised single-task models.
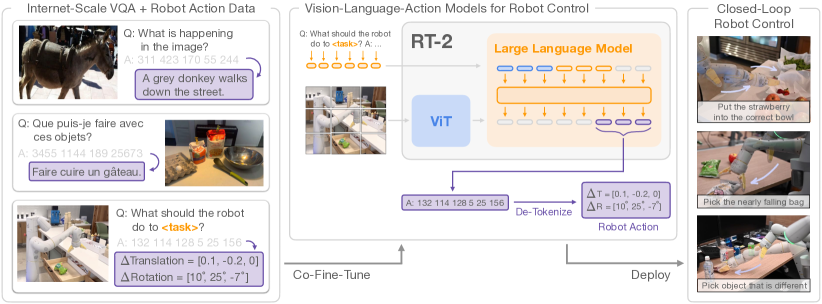
RT-2: VLMs as Robot Policies
RT-2 (Brohan et al. 2023, arXiv:2307.15818) makes a bolder move: directly fine-tune a large Vision-Language Model (PaLI-X, 55B parameters; or PaLM-E) on robot demonstration data, treating robot actions as additional tokens in the language model’s vocabulary.
The key insight: VLMs already encode rich semantic knowledge about objects, actions, and the physical world from internet-scale pre-training. By co-fine-tuning the VLM on robot data (web data and robot demonstrations simultaneously), RT-2 retains this general knowledge while acquiring robot-specific action generation.
Results showed remarkable emergent capabilities: RT-2 could follow instructions like “move the banana to the correct country flag” (requiring reasoning about geography) without any robot demonstrations of this task — it transferred knowledge from the language pre-training.
Open-Source: Octo and OpenVLA
Octo is a 93M-parameter Transformer trained on 800k demonstrations across diverse robots. It supports language and goal-image conditioning, can be fine-tuned to new robots in minutes, and achieves competitive performance with proprietary models on standard benchmarks.
OpenVLA (7B parameters) is based on Prismatic-7B, a VLM fine-tuned on 970k Open X-Embodiment demonstrations. It matches RT-2-55B on several benchmarks while being 7x smaller and open-source.
Generalisation to Novel Tasks
The core promise of foundation model approaches is systematic generalisation. Evaluations show that generalist robot policies can:
- Follow novel language instructions through compositional reasoning
- Adapt to new object instances not seen during training
- Transfer across embodiments with brief fine-tuning
- Exhibit emergent behaviours from language pre-training
Remaining challenges include long-horizon tasks, precise manipulation, and the fundamental data bottleneck — even 130k demonstrations is tiny compared to the billions of tokens used to train language models.
References
- Brohan, A., et al. (2022). RT-1: Robotics Transformer for real-world control at scale. arXiv:2212.06817.
- Brohan, A., et al. (2023). RT-2: Vision-language-action models transfer web knowledge to robotic control. arXiv:2307.15818.
- Ghosh, D., et al. (2023). Octo: An open-source generalist robot policy. arXiv:2405.12213.
- Kim, M. J., et al. (2024). OpenVLA: An open-source vision-language-action model. arXiv:2406.09246.
- Padalkar, A., et al. (2023). Open X-Embodiment: Robotic learning datasets and RT-X models. arXiv:2310.08864.
- Bommasani, R., et al. (2021). On the opportunities and risks of foundation models. arXiv:2108.07258.