
Diffusion Policy: Generative Imitation Learning
Published:
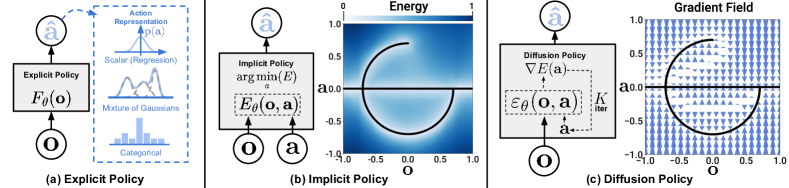
The Multi-Modal Action Problem
Standard behaviour cloning with an MSE loss trains the policy to predict the mean of the expert’s action distribution at each state. This works well when the expert consistently takes similar actions in similar states. But many manipulation tasks are inherently multi-modal: faced with a symmetric object, the expert might grasp from the left or the right with equal frequency. A mean-predicting policy produces an average action that is neither — typically placing the gripper in the middle, where no valid grasp exists.
This is not a pathological edge case; it is the norm in real demonstrations collected by multiple operators or via teleoperation with natural variation. Any policy parameterisation that produces a unimodal action distribution will fail on multi-modal tasks.
Denoising Diffusion Probabilistic Models (DDPM)
Diffusion models learn to generate samples from a data distribution by iteratively denoising Gaussian noise. The forward process adds noise to data over \(T\) steps:
until \(a_T \sim \mathcal{N}(0, I)\). The reverse process learns to denoise:
where the network \(\mu_\theta\) predicts the denoised action (or equivalently, the noise added). The training objective is:
DDPM generates samples by starting from Gaussian noise and iteratively applying the learned denoiser, producing high-quality samples from complex multi-modal distributions.
Diffusion Policy Architecture
Diffusion Policy (Chi et al. 2023, arXiv:2303.04137) applies DDPM to generate sequences of robot actions conditioned on visual observations. Key design choices:
- Action sequences, not single actions: the policy generates a chunk of \(T_p\) future actions simultaneously, providing temporal consistency and avoiding the myopic behaviour of single-step policies.
- Observation conditioning: visual observations (from one or more cameras) are encoded and used to condition the denoising network at each diffusion step.
- Two backbone options: (1) a 1D temporal convolutional network (CNN) for fast inference; (2) a Transformer-based diffusion model for higher capacity.
Conditioning Strategies
Diffusion Policy supports two conditioning strategies:
Classifier-free guidance (CFG): the denoising network is trained both with and without the observation conditioning, and at inference the conditioned and unconditioned predictions are interpolated to sharpen the conditional generation.
Direct conditioning via cross-attention (in the Transformer variant): observation tokens attend to action tokens at each diffusion step, enabling fine-grained conditioning on spatial features.
The CNN backbone uses FiLM conditioning (Feature-wise Linear Modulation) to inject observation features into the denoising network at each layer.
Empirical Results
Chi et al. (2023) evaluated Diffusion Policy on 12 tasks spanning the Robosuite, Robomimic, and Push-T benchmarks. Key findings:
- Diffusion Policy outperforms behaviour cloning with MSE loss by large margins on multi-modal tasks (e.g., +46% success rate on the Can task from Robomimic).
- It also outperforms ACT (Action Chunking with Transformers), the previous state-of-the-art imitation method, on most tasks.
- The CNN backbone is 10x faster at inference than the Transformer backbone, enabling real-time control at 10 Hz.
Real-robot experiments with a UR5 arm demonstrated transfer of policies trained on human demonstrations to physical hardware with minimal fine-tuning.
Connections to Generative Modelling
Diffusion Policy is part of a broader trend of applying generative models to robot learning. Related approaches include:
- BESO (Reuss et al. 2023): diffusion-based goal-conditioned imitation
- Consistency Policy (Prasad et al. 2024): accelerating diffusion inference with consistency models for real-time control
- Flow Matching (Lipman et al. 2022): an alternative generative framework increasingly adopted for robot action generation
References
- Chi, C., et al. (2023). Diffusion policy: Visuomotor policy learning via action diffusion. RSS 2023. arXiv:2303.04137.
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. NeurIPS 2020. arXiv:2006.11239.
- Zhao, T. Z., et al. (2023). Learning fine-grained bimanual manipulation with low-cost hardware. RSS 2023 (ACT paper).
- Song, Y., & Ermon, S. (2019). Generative modelling by estimating gradients of the data distribution. NeurIPS 2019.
- Reuss, M., et al. (2023). Goal-conditioned imitation learning using score-based diffusion policies. RSS 2023.