
3D Vision for Robotics: Point Clouds and Depth
Published:
Why 3D Vision?
A 2D image captures the projection of the world onto a plane, losing all depth information. For a robot arm reaching into a shelf, or a mobile robot navigating a cluttered corridor, knowing the 3D structure of the scene is essential. The geometry of objects — their size, shape, and position in space — determines whether a grasp is feasible, whether a path is collision-free, and how to estimate object pose.
3D perception can be obtained from multiple sources: RGB-D cameras (Microsoft Kinect, Intel RealSense), LiDAR sensors, stereo camera pairs, or monocular depth estimation networks.
Depth Estimation
Stereo depth estimation exploits the disparity between two calibrated cameras. A point at depth \(Z\) from the cameras projects to two image locations separated by a disparity \(d\). With known baseline \(b\) and focal length \(f\):
Classical stereo matching computes disparities by finding corresponding patches across the two images using block matching or semi-global matching (SGM). Deep stereo networks (PSMNet, RAFT-Stereo) achieve state-of-the-art accuracy by learning feature representations and disparity regularisation jointly.
Monocular depth estimation predicts depth from a single image — a fundamentally ill-posed problem that requires learning scene priors. Modern approaches (MiDaS, DPT, Depth Anything) use large Vision Transformers trained on diverse datasets to produce relative depth maps that generalise across domains. Metric depth estimation (predicting absolute scale) is harder and requires training on datasets with ground-truth metric depth.
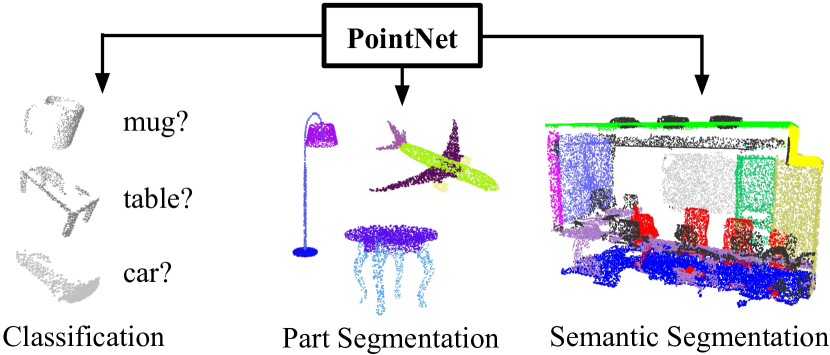
PointNet and PointNet++ for 3D Object Detection
Point clouds — unordered sets of 3D points — are the natural output of LiDAR sensors and depth cameras. Standard CNNs cannot process point clouds directly because they lack grid structure.
PointNet (Qi et al. 2017, arXiv:1612.00593) addresses this with a permutation-invariant architecture: each point is independently processed by a shared MLP, and a global max-pooling aggregates features across all points:
where \(h\) is a shared MLP and \(\gamma\) is another MLP applied to the pooled feature. Max-pooling ensures the output is invariant to point order. PointNet++ extends this with hierarchical grouping: points are clustered into local neighbourhoods, local features are extracted with PointNet, and these are progressively grouped into larger regions — analogous to the hierarchical feature extraction in CNNs.
For 3D object detection from point clouds, architectures like VoxelNet and PointPillars voxelise point clouds into structured grids for efficient 3D convolutions, while PointRCNN and 3DETR operate directly on raw point clouds.
Neural Radiance Fields for Robotics
Neural Radiance Fields (NeRF) (Mildenhall et al. 2020) represent 3D scenes as continuous volumetric functions: a neural network maps a 3D position and viewing direction to colour and volume density. Rendering is performed by volume integration along camera rays, and the network is trained by minimising reconstruction error on a set of posed 2D images.
For robotics, NeRF offers several advantages: it compactly encodes entire 3D scenes, enables novel view synthesis (useful for planning grasps from unexplored viewpoints), and can be integrated with manipulation pipelines. Recent extensions like NeRF-based object detectors, NeRF-RL (training policies in NeRF-reconstructed scenes), and instant-NGP (millisecond NeRF training) have expanded NeRF’s practical robotics utility.
Bird’s Eye View (BEV) Representations
For autonomous driving and outdoor navigation, Bird’s Eye View (BEV) representations project 3D sensor data (cameras, LiDAR) into a top-down grid, making spatial reasoning and path planning more tractable. BEV transformers (BEVFormer, BEVDet) learn to aggregate multi-camera features into a unified BEV grid using cross-attention with 3D positional queries, enabling accurate 3D detection from cameras alone.
References
- Qi, C. R., et al. (2017). PointNet: Deep learning on point sets for 3D classification and segmentation. CVPR 2017. arXiv:1612.00593.
- Qi, C. R., et al. (2017). PointNet++: Deep hierarchical feature learning on point sets in a metric space. NeurIPS 2017.
- Mildenhall, B., et al. (2020). NeRF: Representing scenes as neural radiance fields for view synthesis. ECCV 2020.
- Chang, A. X., et al. (2015). ShapeNet: An information-rich 3D model repository. arXiv:1512.03012.
- Li, Y., et al. (2022). BEVFormer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. ECCV 2022.
- Bochkovskiy, A., et al. (2020). Depth prediction from a single image with monocular depth estimation networks. Multiple CVPR/NeurIPS works.