
World Models: Learning Latent Dynamics
Published:
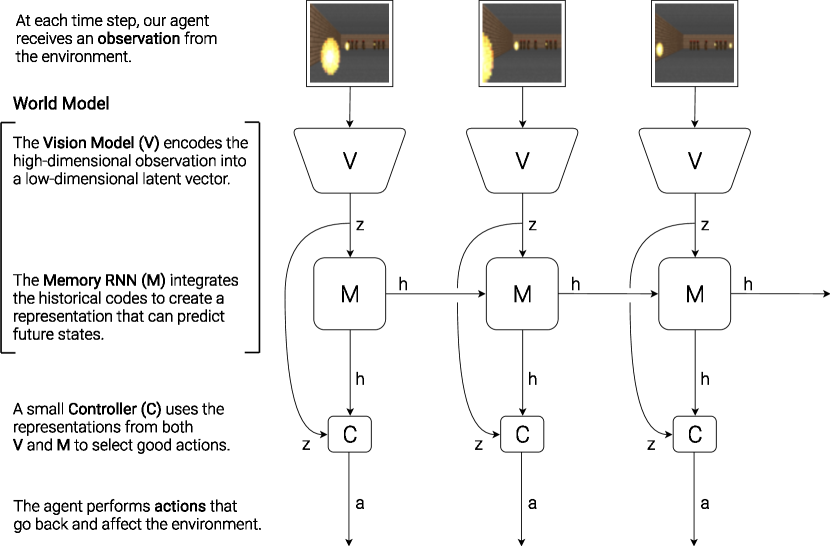
The Biological Inspiration
Neuroscience suggests that the human brain does not directly process raw sensory data at every decision point. Instead, it maintains a compressed, predictive internal model of the world and uses that model to simulate future states. Ha and Schmidhuber’s World Models paper is an explicit computational analogy to this view: a vision module compresses raw pixels, a memory module predicts temporal dynamics, and a tiny controller picks actions based on this summary.
Component 1: The Vision Model (VAE)
The vision model is a Variational Autoencoder (VAE) that maps each raw pixel observation \(x_t\) to a compact latent vector \(z_t\):
The encoder \(q_\phi\) produces a Gaussian distribution over latent codes; the decoder \(p_\psi\) reconstructs the observation. The VAE is trained to minimise reconstruction loss plus a KL regularisation term that keeps the posterior close to a standard Gaussian prior. After training, only the encoder is used: each frame is reduced to a vector \(z_t \in \mathbb{R}^{32}\).
Component 2: The Memory Model (MDN-RNN)
The memory model is a recurrent network with a Mixture Density Network (MDN) head. Given the current latent code \(z_t\) and action \(a_t\), the hidden state \(h_t\) is updated and used to predict a distribution over the next latent code:
The MDN head predicts a mixture of Gaussians over \(z_{t+1}\), capturing the multi-modal stochasticity of environment transitions. This model captures temporal correlations and uncertainty in the environment dynamics.
Component 3: The Controller (CMA-ES)
The controller is a single linear layer:
Its input is the concatenation of the VAE latent code and the RNN hidden state — a rich summary of both the current frame and the history. Despite its simplicity, this controller achieves strong performance because all the representational heavy lifting is done by the vision and memory modules.
The controller is trained with CMA-ES (Covariance Matrix Adaptation Evolution Strategy), a black-box optimisation algorithm. Because the controller has very few parameters (no gradients needed through the environment), CMA-ES is efficient.
Dreaming in Latent Space
The key experiment in the paper is training the controller entirely inside the dream: instead of rolling out the actual environment, the agent generates imaginary trajectories using the MDN-RNN, which acts as a differentiable environment simulator. The reward signal comes from a separate reward predictor head trained alongside the MDN-RNN.
Agents trained in the dream achieve competitive performance on the real environment (VizDoom and Car Racing), demonstrating that a learned world model can serve as a sufficient training ground. This finding prefigures later model-based methods like Dreamer.
Legacy: From World Models to Dreamer
World Models directly inspired the Dreamer family (Hafner et al. 2019, 2020, 2023), which replaces CMA-ES with differentiable policy learning through the world model using reparameterised gradients. DreamerV3 achieves human-level performance across a diverse suite of tasks — including Minecraft diamond collection — with a single set of hyperparameters.
References
- Ha, D., & Schmidhuber, J. (2018). World Models. arXiv:1803.10122.
- Hafner, D., Lillicrap, T., Fischer, I., Villegas, R., Ha, D., Lee, H., & Davidson, J. (2019). Learning Latent Dynamics for Planning from Pixels (PlaNet). ICML. arXiv:1811.04551.
- Hafner, D., Lillicrap, T., Ba, J., & Norouzi, M. (2020). Dream to Control: Learning Behaviors by Latent Imagination (Dreamer). ICLR. arXiv:1912.01603.
- Kingma, D.P., & Welling, M. (2014). Auto-Encoding Variational Bayes. ICLR. arXiv:1312.6114.