
SAC: Soft Actor-Critic and Maximum Entropy RL
Published:
The Maximum Entropy Framework
Standard RL maximises expected cumulative reward. The maximum entropy RL framework adds an entropy bonus at each time step:
Here \(\alpha > 0\) is the temperature parameter controlling the trade-off between reward maximisation and entropy maximisation. High entropy encourages the policy to be spread over actions — exploring rather than prematurely committing. This regularisation leads to more robust policies that generalise better and can capture multi-modal optimal behaviours.
Soft Bellman Equations
The entropy augmentation induces modified Bellman equations, called soft Bellman equations:
The soft value function integrates over actions weighted by the policy, subtracting the log-probability (which is \(-H\)). The optimal soft policy has a Boltzmann (energy-based) form:
This means SAC’s optimal policy naturally spreads probability mass across all high-Q actions.
SAC Architecture
SAC uses three networks: a policy network \(\pi_\theta\), and two Q-networks \(Q_{\phi_1}, Q_{\phi_2}\) (plus their target copies). Using two Q-networks and taking the minimum (clipped double Q-learning) mitigates overestimation bias.
The three training steps are:
- Update critic: minimise soft Bellman residual using transitions from a replay buffer.
- Update actor: minimise \(E_a[\alpha \log \pi_\theta(a \mid s) - Q(s,a)]\) — push mass toward high-Q actions while maintaining entropy.
- Update temperature: adjust \(\alpha\) to meet a target entropy \(\bar{H}\).
Because SAC is off-policy, all three steps can reuse transitions from the replay buffer, giving it a decisive sample efficiency advantage over on-policy methods such as PPO.
Automatic Entropy Tuning
Choosing \(\alpha\) manually is difficult: too large and the agent explores without learning; too small and it collapses to a deterministic policy. SAC v2 (Haarnoja et al. 2018b) automates this by treating \(\alpha\) as a Lagrange multiplier in a constrained optimisation:
where \(\bar{H}\) is a target entropy (typically \(-\dim(\mathcal{A})\) for continuous actions). This dual gradient descent adjusts \(\alpha\) so that the actual policy entropy tracks the target automatically.
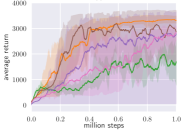
Sample Efficiency and Results
SAC achieves state-of-the-art sample efficiency on continuous control benchmarks (MuJoCo, DeepMind Control Suite). On HalfCheetah and Ant, it matches or exceeds PPO’s asymptotic performance with an order of magnitude fewer environment interactions. The combination of off-policy learning, entropy regularisation, and automatic tuning makes SAC arguably the most practical off-the-shelf algorithm for continuous action spaces.
References
- Haarnoja, T., Zhou, A., Abbeel, P., & Levine, S. (2018). Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. ICML. arXiv:1801.01290.
- Haarnoja, T., Zhou, A., Hartikainen, K., Tucker, G., Ha, S., Tan, J., Kumar, V., Zhu, H., Gupta, A., Abbeel, P., & Levine, S. (2018). Soft Actor-Critic Algorithms and Applications. arXiv:1812.05905.
- Ziebart, B.D., Maas, A.L., Bagnell, J.A., & Dey, A.K. (2008). Maximum Entropy Inverse Reinforcement Learning. AAAI.
- Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347.