
Deep Q-Networks (DQN): Playing Atari from Pixels
Published:
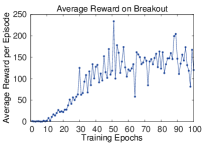
The Deadly Triad: Why Naive Deep Q-Learning Fails
Tabular Q-learning provably converges, but naively replacing the table with a neural network \(Q_\theta(s, a)\) can diverge or oscillate. The culprit is the deadly triad (Sutton & Barto):
- Function approximation: small parameter changes affect all states globally.
- Bootstrapping: using the current Q-estimate as the learning target creates a moving target.
- Off-policy learning: data distribution changes as the policy improves.
The combination of all three — which occurs in deep Q-learning — can cause training instability. DQN addresses issues 1 and 3 with experience replay, and issues 1 and 2 with a target network.
Experience Replay Buffer
Instead of updating on the most recent transition, DQN stores all transitions \((s, a, r, s')\) in a replay buffer \(\mathcal{D}\) of capacity \(N\) (typically 1 million). At each update step, a mini-batch of \(B\) transitions is sampled uniformly at random.
Benefits:
- Breaks temporal correlations: consecutive frames in Atari are highly correlated; random sampling makes the mini-batch approximately i.i.d.
- Data efficiency: each transition can be replayed multiple times.
- Stabilises gradient estimates: reduces variance from correlated samples.
Target Network
The Q-learning loss with a neural network is:
where \(\theta^-\) are the target network parameters — a copy of \(\theta\) that is held frozen for \(C\) steps (e.g., \(C = 10{,}000\)) and then updated by copying \(\theta^- \leftarrow \theta\). This decouples the target from the online network, preventing the feedback loop where the target changes at every gradient step.
CNN Architecture for Atari
The DQN network processes raw Atari frames:
- Preprocessing: crop to 84×84 pixels, convert to grayscale, stack 4 consecutive frames (to capture motion).
- Conv1: 32 filters, 8×8, stride 4 → ReLU
- Conv2: 64 filters, 4×4, stride 2 → ReLU
- Conv3: 64 filters, 3×3, stride 1 → ReLU
- FC: 512 units → ReLU
Output: $$ \mathcal{A} $$ Q-values (one per action)
The single forward pass computes Q-values for all actions simultaneously — efficient for the max operation needed in the Q-learning update.
Training Loop Pseudocode
Initialise Q_θ with random weights
Set Q_{θ⁻} ← Q_θ (target network)
Initialise replay buffer D with capacity N
for t = 1, 2, ..., T:
# Interact with environment
a_t ← ε-greedy action from Q_θ(s_t)
s_{t+1}, r_t ← env.step(a_t)
store (s_t, a_t, r_t, s_{t+1}) in D
# Sample and update
Sample mini-batch {(s,a,r,s')} from D
y = r + γ max_{a'} Q_{θ⁻}(s', a') # target
L = mean((y - Q_θ(s,a))²)
Update θ via SGD/Adam on L
# Periodic target update
if t mod C == 0: θ⁻ ← θ
Rewards are clipped to \([-1, +1]\) to bound the magnitude of error gradients across games with different score scales.
Human-Level Performance on Atari
DQN was evaluated on 49 Atari 2600 games from the Arcade Learning Environment, trained from raw pixels with the same hyperparameters for each game. Key results:
- Surpasses human performance on 29 of 49 games.
- Strong results on: Pong, Breakout, Space Invaders, Q*bert.
- Weak results on: games requiring long-horizon planning (Montezuma’s Revenge — the classic hard exploration problem).
The 2013 arXiv preprint showed the initial Atari results on 7 games; the 2015 Nature paper scaled to 49 games with the improved architecture and target network.
References
- Mnih, V., Kavukcuoglu, K., Silver, D., et al. (2015). Human-level control through deep reinforcement learning. Nature, 518, 529–533.
- Mnih, V., et al. (2013). Playing Atari with deep reinforcement learning. arXiv:1312.5602.
- van Hasselt, H., Guez, A., & Silver, D. (2016). Deep reinforcement learning with double Q-learning. AAAI 2016.