
LongRoPE: Extending Context to 2 Million Tokens
Published:
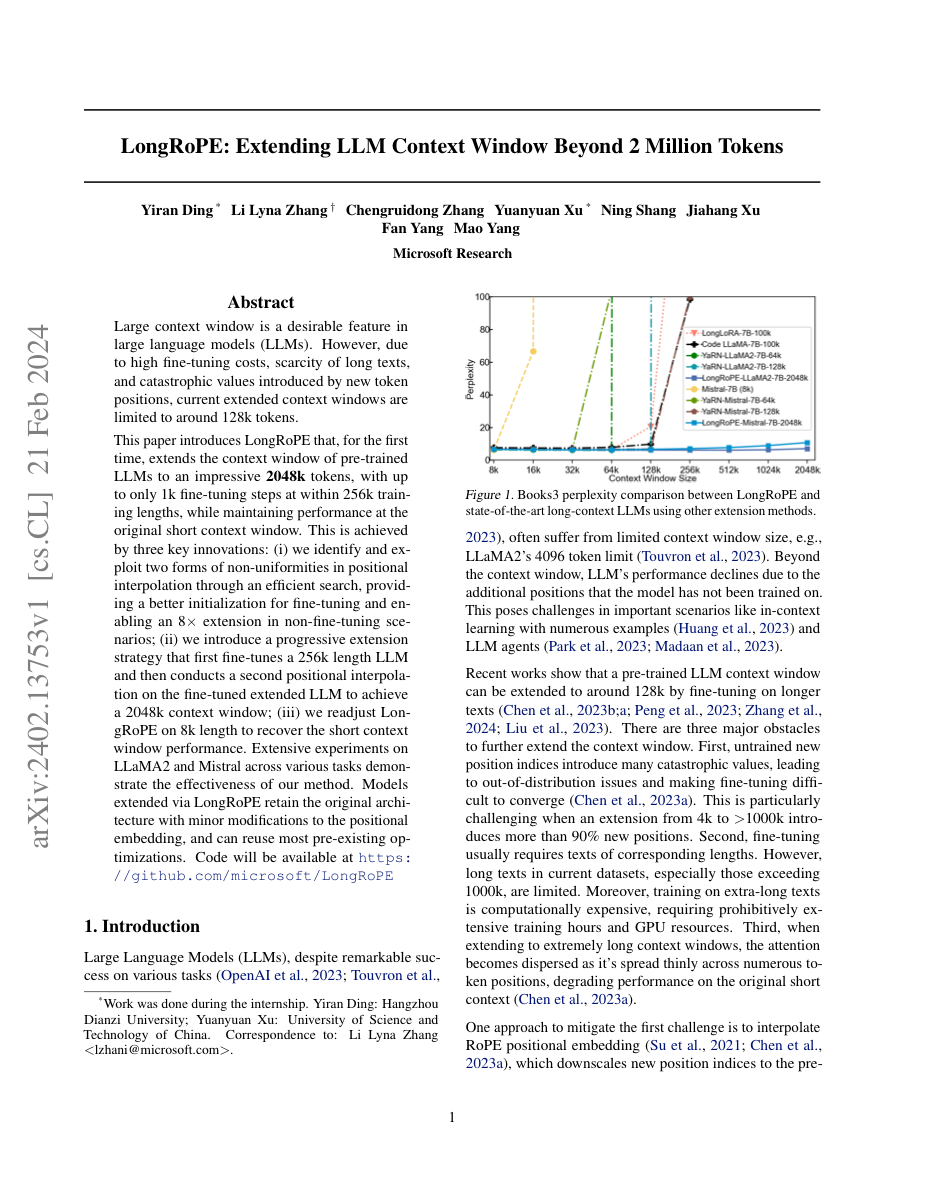
Pushing Beyond YaRN
YaRN divides RoPE dimensions into three zones (high-freq, mid-freq, low-freq) with a hand-designed blending function. This works well up to ~128k tokens. But at extreme lengths — 512k, 1M, 2M — the approximation breaks down.
LongRoPE (Ding et al., Microsoft Research, 2024) takes a fundamentally different approach: instead of designing the rescaling analytically, search for the optimal per-dimension rescaling factors directly.
The Core Idea: Per-Dimension Search
In standard RoPE, each dimension pair i uses frequency θᵢ. To extend context, all methods modify these frequencies. LongRoPE generalises: each dimension i gets its own learned rescaling factor λᵢ:
Setting all λᵢ = s (the scale factor) gives linear interpolation. Setting λᵢ via the NTK formula gives NTK scaling. YaRN approximates the optimal λᵢ with a three-zone formula.
LongRoPE instead searches for the optimal vector λ = [λ₀, λ₁, …, λ_{d/2-1}] directly using an evolutionary search algorithm (specifically, a variant of CMA-ES — Covariance Matrix Adaptation Evolution Strategy).
The Evolutionary Search
Objective function: on a set of long-context validation documents, evaluate perplexity for a given λ vector.
Search procedure:
- Initialise λ using YaRN’s formula as a warm start
- Run evolutionary search (population of candidate λ vectors)
- For each candidate: compute attention scores with modified RoPE, measure perplexity
- Select best candidates, apply mutations, repeat
- Return λ that achieves minimum perplexity on long sequences
The search is done with the frozen original model weights — no gradient updates. Only λ is optimised (it is not a learned parameter in the usual sense; it is found by black-box search).
The Big Picture
LongRoPE shows that long-context extension is not just about “stretching positions.” At extreme lengths, different rotary dimensions need different treatment, and brute-force search can outperform hand-designed formulas.
The Two-Stage Training Pipeline
After finding λ via search, LongRoPE uses two short fine-tuning stages:
Stage 1: Extreme extension (e.g., 2M tokens)
- Apply the searched λ
- Fine-tune for ~400 steps on long documents (8k–128k sequence length)
- This adapts the model weights to the new rotary frequencies at maximum context
Stage 2: Short-context recovery
- The model after Stage 1 performs slightly worse at short contexts
- Fine-tune with a smaller λ (less aggressive rescaling) for ~200 steps
- This recovers near-original performance at the original training length
The two-stage approach is crucial: Stage 1 enables long context, Stage 2 prevents short-context regression — a problem that YaRN and NTK methods also face but do not explicitly address.
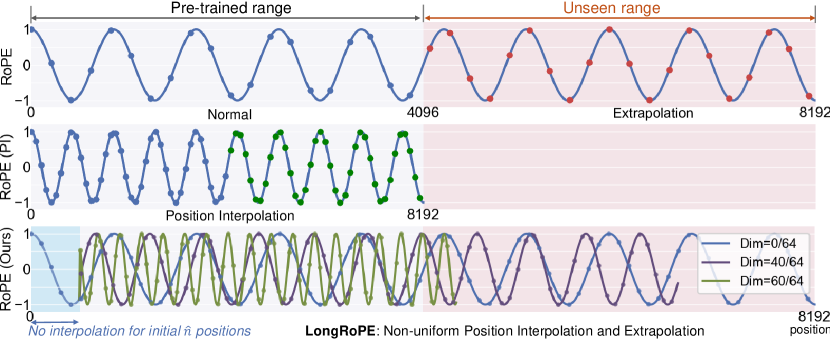
Visual: Uniform vs Non-Uniform Rescaling
Non-Uniform Optimal Rescaling
A key empirical finding from LongRoPE: the optimal λᵢ values are highly non-uniform across dimensions. Some dimensions benefit from aggressive rescaling (large λᵢ), others benefit from almost none (λᵢ ≈ 1).
This explains why the three-zone approximation of YaRN works only up to moderate scales — at extreme lengths, the true optimal is complex enough that a three-zone formula is too coarse.
The searched λ vector typically shows:
- Irregular oscillation rather than a clean monotone function of i
- Some high-frequency dimensions needing no rescaling
- Some mid-frequency dimensions needing more rescaling than YaRN assigns
Why Evolutionary Search Works Here
The evolutionary search for λ is feasible because:
- Objective is cheap to evaluate: given candidate λ, compute perplexity on a small set of long documents (no gradient, just a forward pass).
- Problem is low-dimensional: λ has only d/2 = 64 values for a typical head. CMA-ES handles this scale easily.
- Good warm start: initialising from YaRN’s formula gives the search a sensible starting point rather than random noise.
- Model weights stay frozen: the search cannot overfit — it can only find λ values that work well for the existing model.
A single search run (a few thousand forward passes) is far cheaper than thousands of fine-tuning steps.
Results
LongRoPE was evaluated on LLaMA 2-7B extended to various lengths:
| Method | 4k | 8k | 32k | 128k | 256k | 512k |
|---|---|---|---|---|---|---|
| YaRN | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
| LongRoPE | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
LongRoPE maintains near-original perplexity at 512k tokens. At 2M tokens (the headline result), perplexity increases but the model remains functional for tasks like document retrieval.
Comparison of Context Extension Methods
| Method | Max practical extension | Per-dim tuning | Fine-tuning | Short-context recovery |
|---|---|---|---|---|
| Linear interp | ~8× | No (uniform) | ~1000 steps | Partial |
| NTK scaling | ~4× | No (formula) | Optional | No |
| YaRN | ~32× | Approximate (3 zones) | ~400 steps | No |
| LongRoPE | ~1000× | Yes (searched) | ~600 steps | Yes (Stage 2) |
Where LongRoPE Is Used
- Phi-3 (Microsoft): Phi-3-mini and Phi-3-small use LongRoPE for 128k context
- Phi-3.5-MoE: Also uses LongRoPE
- The technique is increasingly adopted in models targeting very long contexts
Summary
LongRoPE’s key contributions:
- Per-dimension rescaling: each frequency gets its own λᵢ instead of a global formula
- Evolutionary search: finds optimal λ without gradient updates, using only perplexity as signal
- Two-stage fine-tuning: Stage 1 for long context, Stage 2 for short-context recovery
- Extreme extension: enables 2M-token context, well beyond what NTK or YaRN can handle
LongRoPE represents the current frontier of positional encoding research — pushing language models toward contexts that can fit entire books, codebases, or hours of transcribed audio.
References
- Ding, Y., Zhang, L., Zhang, C., Xu, G., Yang, Y., Su, L., Zhao, S., & Liu, T.-Y. (2024). LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens. arXiv 2024 (LongRoPE: non-uniform RoPE rescaling with progressive extension stages, enabling 2M-token context in LLMs).
- Su, J., Lu, Y., Pan, S., Murtadha, A., Wen, B., & Liu, Y. (2021). RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv 2021 (RoPE: the positional encoding that LongRoPE extends via dimension-specific rescaling factors).
- Peng, B., Quesnelle, J., Fan, H., & Shippole, E. (2023). YaRN: Efficient Context Window Extension of Large Language Models. ICLR 2024 (YaRN: the intermediate approach that LongRoPE builds upon with non-uniform and search-based rescaling).