
MPNN: The General Message Passing Neural Network Framework
Published:
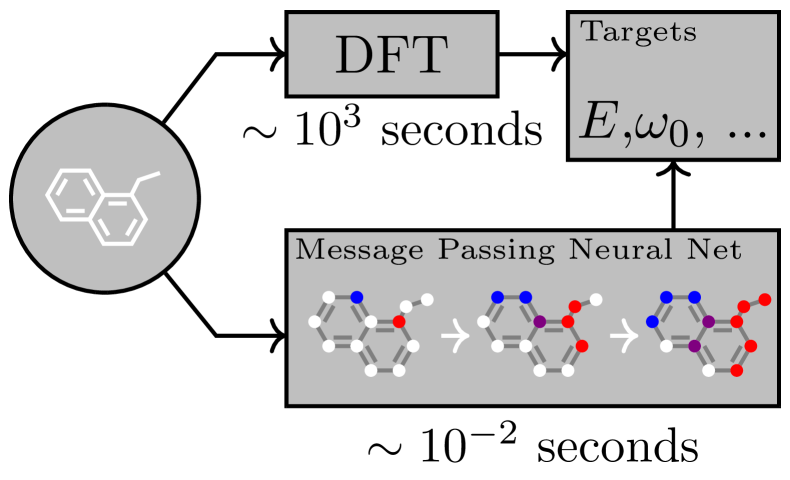
Intuition First: What Is Message Passing?
Imagine a group of friends, each holding a colored card. In each round, everyone passes their card color to their neighbors, who blend the incoming colors with their own. After K rounds, each person’s card encodes a summary of their K-hop social circle. That is message passing: iterative local information exchange that builds up increasingly global representations.
Why a Unified Framework?
By 2017, several successful GNN architectures existed — GCN, GGNN (Gated Graph Neural Network), Interaction Networks, etc. Each was described differently, making comparison and design difficult.
Gilmer et al. (2017) introduced MPNN to unify all spatial GNNs under one abstraction. This framework:
- Makes design choices explicit and comparable
- Enables systematic ablation and design
- Identifies what is shared and what differs between architectures
- Reveals the fundamental limits of the class (later formalised by the WL test)
The MPNN Framework
A single MPNN layer for node v computes:
Phase 1 — Message Computation:
For each neighbour u of v, compute a message. The message can depend on the sender’s state h_u, the receiver’s state h_v, and the edge feature e_{uv}.
Phase 2 — Aggregation:
Aggregate all messages from neighbours. □ must be permutation-invariant (the order of neighbours does not matter): sum, mean, max, LSTM (with a random permutation of neighbours).
Phase 3 — Update:
Combine the aggregated message with the node’s previous state to produce the new state.
After K rounds, each node’s representation h^{(K)}_v encodes information from its K-hop neighbourhood.
Concrete Worked Example: One MPNN Step
Consider a tiny graph: nodes A, B, C where A–B and B–C are edges. All nodes have scalar features: h_A=1, h_B=2, h_C=3. Using GCN as an instance (message = W·h_u, aggregation = mean, W=I):
Step for node B (neighbours: A and C):
- Message from A: m_{A→B} = h_A = 1
- Message from C: m_{C→B} = h_C = 3
- Aggregation: m_B = mean(1, 3) = 2.0
- Update: h_B’ = ReLU(h_B + m_B) = ReLU(2 + 2) = 4
Step for node A (neighbour: B only):
- Message from B: m_{B→A} = h_B = 2
- Aggregation: m_A = 2.0
- Update: h_A’ = ReLU(1 + 2) = 3
After one step, h_A has absorbed B’s information; h_B has blended A and C. After two steps, h_A would know about C — its 2-hop neighbour.
Popular GNNs as MPNN Instances
| Model | Message M | Aggregation □ | Update U |
|---|---|---|---|
| GCN | (Ã h_u) / √(d_u d_v) | Sum | Linear + ReLU |
| GraphSAGE | W h_u | Mean (or max) | W [h_v ‖ agg] + ReLU |
| GAT | α_{uv} W h_u | Sum | ReLU |
| GIN | h_u | Sum | MLP( (1+ε)h_v + Σ h_u ) |
| MPNN (original) | r(h_u, e_{uv}) | Sum | GRU(h_v, m_v) |
Where r is a learned edge network and GRU is a gated recurrent unit.
Edge Features in MPNN
A key advantage of the MPNN formulation: edge features are first-class citizens. The message function M can freely use e_{uv}:
Where A is a learned edge-specific linear map (the “edge network” idea from Gilmer et al.). This is essential for molecules where bond types (single, double, aromatic) are critical features.
Readout for Graph-Level Prediction
After K message-passing rounds, MPNN computes a graph-level representation via a readout function:
The readout R must be permutation-invariant. Common choices:
- Sum: h_G = Σ h_v (sensitive to graph size)
- Mean: h_G = (1/N) Σ h_v (normalised)
- Set2Set: an attention-based readout with memory
The Limits of MPNN
All MPNN models share the same fundamental limitation: their expressive power is bounded by the 1-Weisfeiler-Lehman graph isomorphism test (1-WL test, see the Expressivity section).
Any two graphs that are indistinguishable by 1-WL are also indistinguishable by any MPNN. Graphs with identical multisets of k-hop neighbourhood features cannot be told apart, regardless of the specific M, □, and U functions.
This limitation motivates:
- Higher-order GNNs (k-WL for k > 1)
- Structural encodings (adding positional/structural features that break symmetry)
- Graph Transformers (attend globally, not just to neighbours)
Practical Implementation
In PyTorch Geometric, MPNN-style models are implemented by inheriting MessagePassing:
class MyGNNLayer(MessagePassing):
def __init__(self):
super().__init__(aggr='sum') # □ = sum
def forward(self, x, edge_index, edge_attr):
return self.propagate(edge_index, x=x, edge_attr=edge_attr)
def message(self, x_j, edge_attr):
# M: message from j to i
return self.edge_net(edge_attr) @ x_j.unsqueeze(-1)
def update(self, aggr_out, x):
# U: update node state
return self.gru(aggr_out, x)
Summary
The MPNN framework captures every spatial GNN in three functions:
| Function | Role | Must satisfy |
|---|---|---|
| M (message) | Compute edge messages | Can use sender, receiver, edge features |
| □ (aggregation) | Combine neighbour messages | Permutation invariant |
| U (update) | Update node state | Combines old state + aggregate |
The space of MPNNs is defined by choices for M, □, and U. Understanding this space — and its limits — is the foundation for understanding all GNN research from 2016 to the present.
References
- Gilmer, J., Schütt, K. T., Matera, G., Deisenroth, M. P., & Müller, K.-R. (2017). Neural Message Passing for Quantum Chemistry. ICML 2017.
- Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., & Bengio, Y. (2018). Graph Attention Networks. ICLR 2018.
- Hamilton, W. L., Ying, R., & Leskovec, J. (2017). Inductive Representation Learning on Large Graphs. NeurIPS 2017.