
DiffPool: Learning Hierarchical Graph Pooling
Published:
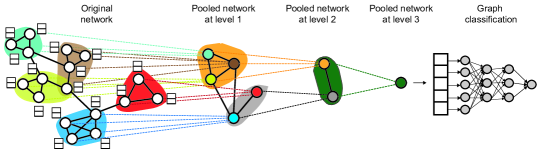
Intuition First: Hierarchical Pooling as a Convolutional Pyramid
In image CNNs, max-pooling after each conv layer progressively coarsens the spatial grid: 32×32 → 16×16 → 8×8 → 1×1. This captures multi-scale features — edges at fine scale, shapes at coarser scale, objects at the coarsest. DiffPool brings this pyramid idea to graphs: nodes → clusters → super-clusters → graph. The key challenge is that unlike pixels, graph nodes have no fixed spatial ordering, so the pooling must be learned and permutation-invariant.
The Limitation of Flat Global Pooling
Global mean/sum/max pooling jumps directly from N node embeddings to a single graph embedding. For graphs with hierarchical structure — like molecules (atoms → functional groups → whole molecule) or social networks (people → communities → factions) — this skips all intermediate scales.
CNNs solve this with hierarchical pooling (max-pool after each conv layer). DiffPool brings the same idea to graphs, with the key challenge: graph pooling must be permutation-invariant and must handle variable numbers of nodes.
The DiffPool Architecture
DiffPool processes each pooling level l with two GNNs:
1. Embedding GNN — computes node embeddings:
2. Pooling GNN — computes cluster assignments:
S^{(l)} ∈ ℝ^{N_l × k_l} is the soft assignment matrix: S[i,j] is the probability that node i belongs to cluster j. softmax is applied row-wise.
Coarsening: compute the next level’s adjacency and embeddings:
The new adjacency A^{(l+1)} is the cluster-to-cluster connectivity — how much two clusters share edges through their constituent nodes.
Why Soft Assignment?
Hard assignment (each node assigned to exactly one cluster) would require argmax — not differentiable. Soft assignment (each node fractionally assigned to all clusters) allows end-to-end gradient flow.
The assignment S^{(l)} is learned jointly with the rest of the network. The model discovers which nodes should be clustered together — without any external supervision on the clustering.
Auxiliary Loss Terms
DiffPool adds two regularisation losses to guide clustering quality:
Link prediction loss: encourages nodes connected by an edge to be assigned to the same cluster:
If S^{(l)} S^{(l)T} approximates A^{(l)}, clusters are graph-connected.
Entropy loss: encourages each node’s assignment to be concentrated (not uniformly spread):
Where H is entropy. Low entropy → sharp cluster assignment → more interpretable clusters.
Concrete Worked Example: One DiffPool Step
Suppose we have 4 nodes and want to pool to 2 clusters. After GNN_embed, node embeddings Z ∈ ℝ^{4×3}:
Z = [[1, 0, 1], # node 0
[1, 0, 0], # node 1 — similar to node 0
[0, 1, 1], # node 2
[0, 1, 0]] # node 3 — similar to node 2
GNN_pool outputs raw logits, softmax → assignment S ∈ ℝ^{4×2}:
S = [[0.9, 0.1], # node 0 → mostly cluster A
[0.8, 0.2], # node 1 → mostly cluster A
[0.1, 0.9], # node 2 → mostly cluster B
[0.2, 0.8]] # node 3 → mostly cluster B
New cluster embeddings: H’ = S^T Z ∈ ℝ^{2×3}:
H'[A] = 0.9×[1,0,1] + 0.8×[1,0,0] + 0.1×[0,1,1] + 0.2×[0,1,0]
≈ [1.7, 0.3, 0.9] (cluster A = nodes 0+1)
H'[B] = 0.1×[1,0,1] + 0.2×[1,0,0] + 0.9×[0,1,1] + 0.8×[0,1,0]
≈ [0.3, 1.7, 1.0] (cluster B = nodes 2+3)
The soft assignment correctly merged structurally similar nodes (0,1) into cluster A and (2,3) into cluster B — learned purely from features and graph structure.
Computational Cost
DiffPool runs two GNNs at each level. For a graph with N nodes coarsened to k clusters:
- Forward pass: O(N² d) for the dense assignment matrix
- Memory: O(N²) — DiffPool operates on dense adjacency matrices
This makes DiffPool quadratic in N — practical for graphs with hundreds of nodes (molecules), but not for social networks or knowledge graphs with millions of nodes.
When DiffPool Helps
DiffPool outperforms flat pooling when:
- The task requires multi-scale understanding: molecular property prediction benefits from atom-level and functional-group-level representations simultaneously
- Graphs have natural hierarchical structure: trees, clustered communities, hierarchical molecules
- The graph is small enough: typically ≤ 1000 nodes
It is a standard strong baseline on the TUDataset graph classification benchmarks (PROTEINS, MUTAG, IMDB, RDT).
Limitations
- Quadratic memory: no scaling to large graphs
- Fixed number of clusters: must specify k^{(l)} per level before training
- No guarantee of meaningful clusters: the auxiliary losses help but do not force semantically meaningful groupings
- Sensitive to the number of pooling levels: too many levels → over-compression; too few → flat pooling
Summary
| Component | Role |
|---|---|
| GNN_{embed} | Compute node representations at this scale |
| GNN_{pool} | Learn soft cluster assignments |
| S^T Z | Aggregate node embeddings into cluster embeddings |
| S^T A S | Coarsen adjacency to cluster graph |
| L_{LP} + L_E | Encourage connectivity-aligned, sharp clusters |
DiffPool introduced the idea of learned hierarchical pooling for graphs — differentiable, end-to-end, and structure-aware. Its quadratic complexity limits scale, but for small-graph tasks (molecules, proteins), it remains a reference architecture.
References
- Ying, R., You, J., Morris, C., Ren, X., Hamilton, W. L., & Leskovec, J. (2018). Hierarchical Graph Representation Learning with Differentiable Pooling. NeurIPS 2018.
- Simonovsky, M., & Komodakis, N. (2018). Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs. CVPR 2017.