
HAN: Heterogeneous Graph Attention Networks
Published:
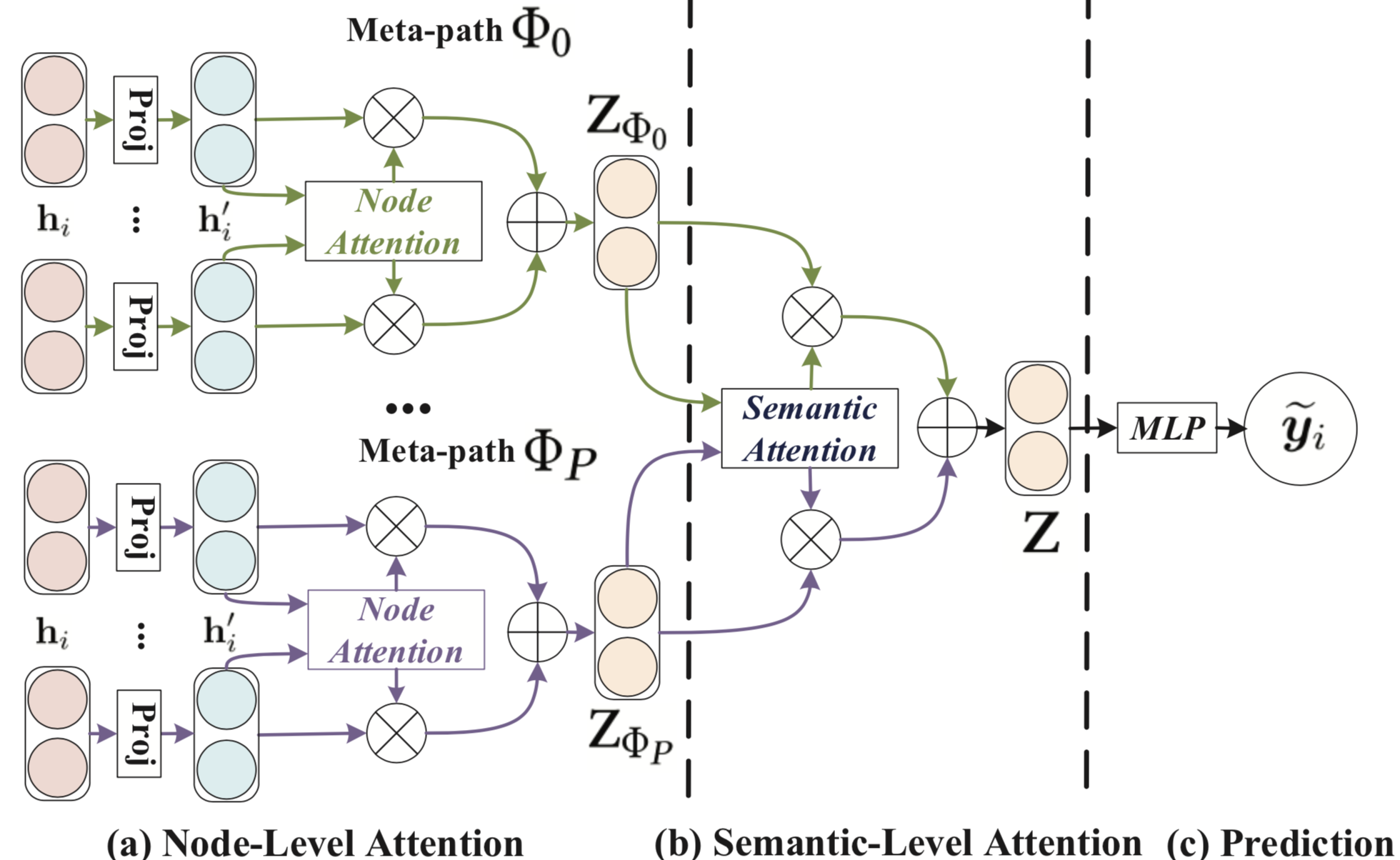
The Two-Level Attention Idea
HAN’s key insight: in a heterogeneous graph, not all neighbours are equally informative, and not all relationship types are equally relevant to the task. Two separate attention mechanisms handle these two sources of variability.
- Node-level attention: given a meta-path Φ, weight the importance of different neighbours connected via Φ
- Semantic-level attention: weight the importance of different meta-paths Φ₁, …, Φ_P for the overall prediction
Step 1: Meta-Path-Based Neighbour Projection
For each meta-path Φ, the heterogeneous graph contains a projected meta-path graph: a homogeneous graph where an edge connects node u to node v if there exists a path of type Φ between them.
For example, in an academic network:
- APA (Author → Paper → Author): co-authorship graph
- APCPA (Author → Paper → Conference → Paper → Author): same-venue collaboration graph
Each meta-path gives a different view of the Author-Author relationships.
Before attention, project all node features to a common dimension (since different node types may have different feature dimensions):
Step 2: Node-Level Attention (Within Meta-Path)
For a given meta-path Φ, apply GAT-style attention over meta-path neighbours:
Compute unnormalised attention between nodes i and j:
| Where a^Φ ∈ ℝ^{2d’} is a meta-path-specific attention vector and | denotes concatenation. |
Normalise with softmax:
Aggregate:
z^Φ_i is node i’s embedding under meta-path Φ. With multi-head attention, concatenate K heads:
Step 3: Semantic-Level Attention (Across Meta-Paths)
After computing {z^{Φ_1}_i, …, z^{Φ_P}_i}, we need to combine them. Each meta-path may contribute differently to the task.
Learn a meta-path importance score β^{Φ_p} (shared across nodes, since a meta-path’s importance is a global property):
Normalise:
Final embedding:
Full HAN Pipeline
Input: Heterogeneous graph G with multiple node/edge types
Pre-defined meta-paths {Φ₁, ..., Φ_P}
For each meta-path Φ_p:
1. Project node features to common space
2. Construct meta-path graph (who is connected via Φ_p?)
3. Apply node-level GAT attention → z^{Φ_p}_i for each node
Semantic-level attention:
4. Compute meta-path importance β^{Φ_p}
5. Weighted combination: h_i = Σ_p β^{Φ_p} z^{Φ_p}_i
Classifier:
6. MLP(h_i) → ŷ_i
Worked Example: Semantic Attention Weights
Suppose we have two meta-paths for author classification:
- APA (Author → Paper → Author): co-authorship
- APCPA (Author → Paper → Conference → Paper → Author): same-venue collaboration
After node-level attention, author i has two embeddings: z^APA_i and z^APCPA_i.
Semantic attention computes importance scores (averaged over all authors):
w_APA = (1/|V|) Σ_i q^T · tanh(W · z^APA_i + b) → suppose w_APA = 0.8
w_APCPA = (1/|V|) Σ_i q^T · tanh(W · z^APCPA_i + b) → suppose w_APCPA = 0.3
After softmax normalisation:
β_APA = exp(0.8) / (exp(0.8) + exp(0.3)) ≈ 2.23 / (2.23 + 1.35) ≈ 0.62
β_APCPA = exp(0.3) / (exp(0.8) + exp(0.3)) ≈ 1.35 / (2.23 + 1.35) ≈ 0.38
Final embedding: h_i = 0.62 · z^APA_i + 0.38 · z^APCPA_i
The model has learned that co-authorship is 1.6× more informative than same-venue for research area prediction — a result that matches domain intuition and emerges from the data without manual weighting.
Limitations
Manual meta-path definition: domain knowledge required to define meaningful meta-paths. Wrong meta-paths → poor performance.
Combinatorial explosion: for complex HINs with many relation types, the number of meaningful meta-paths grows combinatorially.
Node-type coverage: HAN focuses on target node type; other node types are only intermediaries in meta-paths.
Scalability: constructing meta-path graphs and running multiple GATs is expensive for large graphs.
Later architectures (HGT: Heterogeneous Graph Transformer) address these by learning relation-specific attention without explicit meta-path definition.
Summary
| Component | What it learns |
|---|---|
| Node projection W_{τ(v)} | Common embedding space across types |
| Node-level attention α^Φ_{ij} | Which neighbours matter (per meta-path) |
| Semantic attention β^{Φ_p} | Which meta-paths matter (per task) |
| Multi-head node attention | Multiple perspectives within each meta-path |
HAN was the first model to apply hierarchical attention to heterogeneous graphs, showing that the which-relation matters as much as the which-neighbour problem in complex multi-relational data.
References
- Wang, X., Ji, H., Shi, C., Wang, B., Ye, Y., Cui, P., & Yu, P. S. (2019). Heterogeneous Graph Attention Network. WWW 2019.
- Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., & Bengio, Y. (2018). Graph Attention Networks. ICLR 2018 (base GAT that HAN extends).
- Hu, Z., Dong, Y., Wang, K., & Sun, Y. (2020). Heterogeneous Graph Transformer. WWW 2020 (successor to HAN without explicit meta-paths).