
Graph Transformers: Bringing Attention to Graphs
Published:
The Limits of Local Message Passing
Standard GNNs (GCN, GAT, GIN, GraphSAGE) aggregate information only from direct neighbours. To reach a node k hops away, you need k layers. Problems:
- Long-range dependencies: for diameter-10 graphs, you need 10 layers — causing over-smoothing
- Over-squashing: information from exponentially many nodes must be compressed through bottleneck edges (see the Over-squashing post)
- Structural rigidity: the message-passing graph IS the computation graph
The solution: full attention — every node attends to every other.
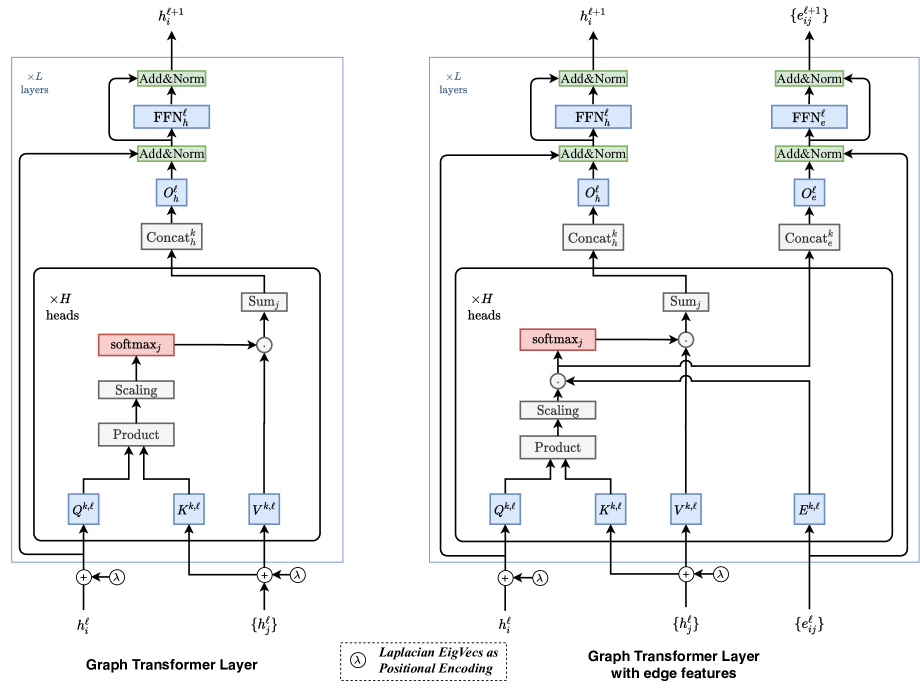
Graph Transformer Architecture
A Graph Transformer layer is essentially a standard Transformer self-attention layer, but applied to graph nodes:
Where b_{ij} is an optional attention bias encoding the graph structure between nodes i and j.
Without b_{ij}: the model ignores the graph and is a standard Transformer on node features.
With b_{ij}: graph structure guides attention (edge presence, distance, structural similarity).
The Key Challenge: Positional Encodings for Graphs
Sequences have a natural positional order (position 1, 2, 3, …). Graphs do not — there is no canonical node ordering. Without positional information, nodes with identical features but different structural roles are indistinguishable.
Graph Transformers use graph-based positional encodings (covered in depth in the Graph PE section):
- Laplacian eigenvectors: the k smallest eigenvectors of the graph Laplacian
- Random walk PEs: landing probabilities from node i to node j in k steps
- Shortest path distances: encoded as integer biases on attention scores
Graphormer (2021)
Graphormer (Ying et al., Microsoft) biases attention scores by three structural features:
- Spatial encoding: b_{ij} = φ(dist(i,j)) — a learned function of the shortest path distance
- Edge encoding: for each edge on the path i→j, add edge features to the attention score
- Centrality encoding: add degree-based biases to node embeddings at input
Graphormer achieved state-of-the-art on OGB-LSC molecular property prediction (PCQM4Mv2).
SAN (Spectral Attention Network)
SAN (Kreuzer et al., 2021) uses Laplacian eigenvectors as positional encodings and computes full attention over all node pairs, distinguishing connected from non-connected pairs:
Separate query-key matrices for existing edges and non-edges — the model can attend differently to connected and non-connected nodes.
GPS (General, Powerful, Scalable Graph Transformer)
GPS (Rampášek et al., 2022) combines:
- Local message passing (GCN/GAT/GIN): captures local structural patterns efficiently
- Global self-attention (Transformer): captures long-range dependencies
GPS layer:
h_local ← local MPNN(h, A) # O(|E| · d)
h_global ← self-attention(h) # O(N² · d)
h_out ← LN(h + h_local + h_global) + FFN
GPS achieves state-of-the-art on the Long-Range Graph Benchmark (LRGB) — a benchmark specifically designed to test long-range dependency learning.
Complexity: The O(N²) Challenge
Full attention on graphs of N nodes costs O(N²) — the same as self-attention in Transformers.
For small graphs (molecules with N < 100): no problem. For large graphs (social networks with N > 100,000): prohibitive.
Solutions:
- K-nearest-neighbor attention: each node attends to only its K nearest neighbours in feature space
- Linformer-style: approximate full attention with a low-rank decomposition
- Cluster-based: run full attention within clusters, then inter-cluster attention
Summary
| Property | Local MPNN (GCN, GAT) | Graph Transformer | ||
|---|---|---|---|---|
| Receptive field | K-hop (K = number of layers) | All nodes (direct) | ||
| Long-range dependencies | Requires many layers (oversmoothing) | Handled directly | ||
| Complexity | O(K · | E | · d) | O(N² · d) |
| Graph structure encoding | Adjacency (message passing) | Positional encodings + attention biases | ||
| Suitable graph size | Any (with neighbour sampling) | Small-medium (N < 10,000) | ||
| Over-squashing | Yes | No |
Graph Transformers trade O(N²) computation for the ability to directly connect any pair of nodes. For small graphs (molecules, proteins, small networks), this is the current state of the art. For large graphs, GPS-style hybrid approaches (local MPNN + global attention) are the practical frontier.
References
- Dwivedi, V. P., & Bresson, X. (2021). A Generalization of Transformers to Graphs. arXiv preprint.
- Kreuzer, D., Beaini, D., Hamilton, W. L., Létourneau, V., & Tossou, P. (2021). Rethinking Graph Transformers with Spectral Attention. NeurIPS 2021.
- Rampasek, L., Galkin, M., Dwivedi, V. P., Lim, A. T., Wolf, G., & Beaini, D. (2022). Recipe for a General, Powerful, Scalable Graph Transformer. NeurIPS 2022 (GPS).
- Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). Attention Is All You Need. NeurIPS 2017.